
Introduction
The research efforts in this post are geared towards two key objectives: the first being to extract an instinctual understanding from the given prompt, and the second is to develop examples of evaluation problems that embody this innate comprehension that lies within the prompt.
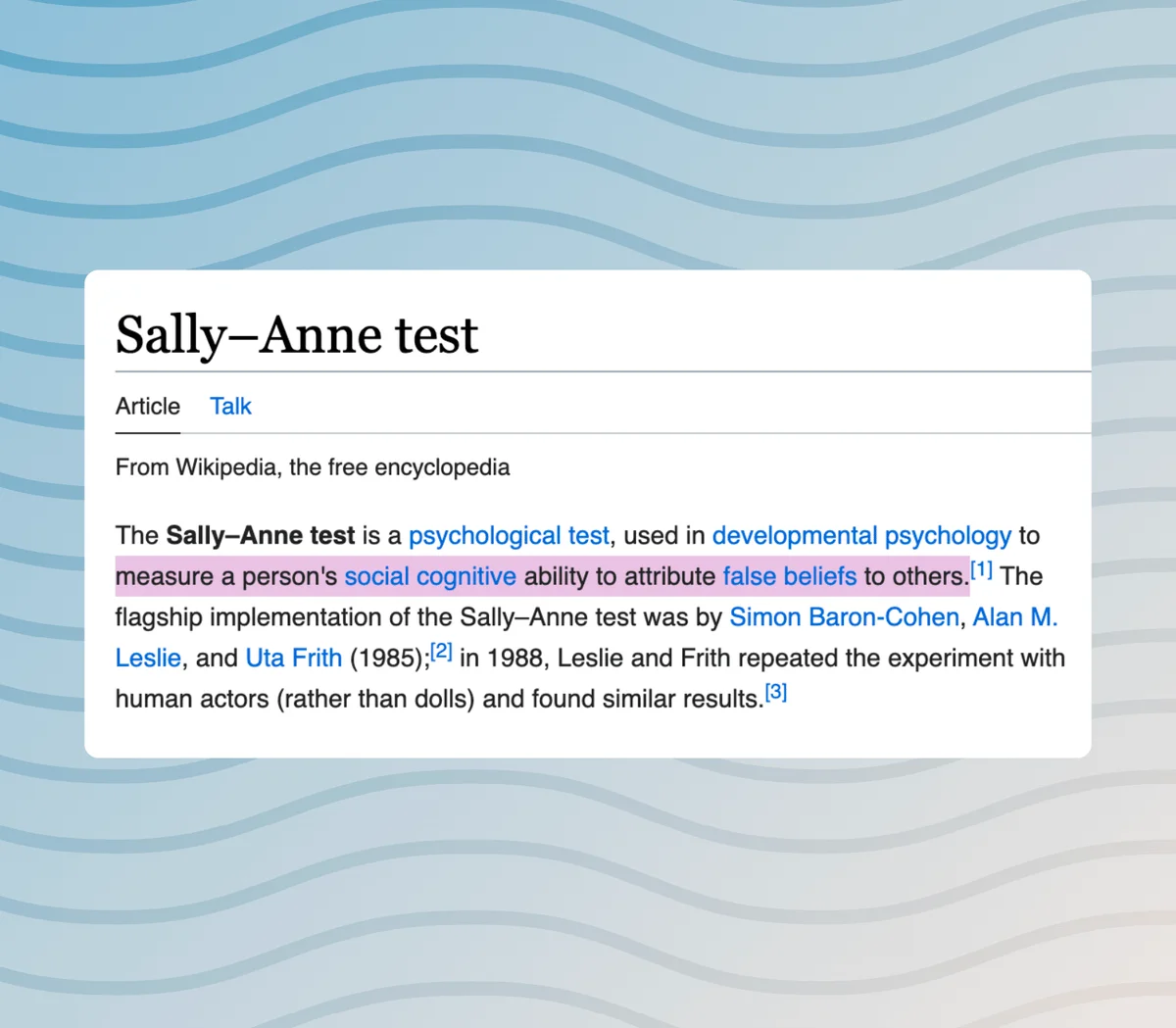
Today, I bring into focus a commonly known cognitive assessment tool, the Sally-Anne False Belief Test.
Framework
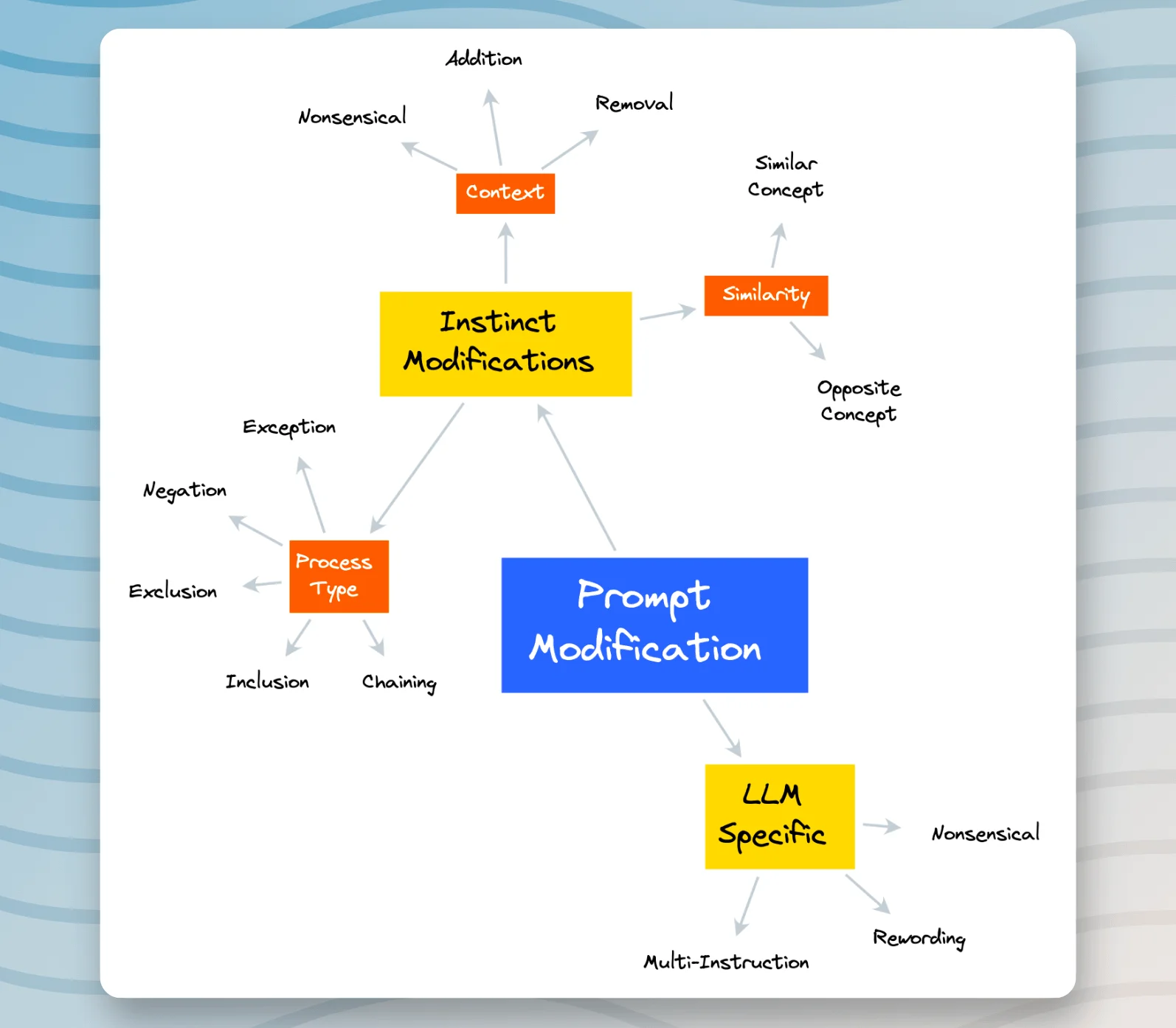
As part of this exploration, I've roughly outlined a framework that represents the process I am intending to explore through testing, designing, and adaptation for the purpose of evaluation. This framework is three-pronged, including:
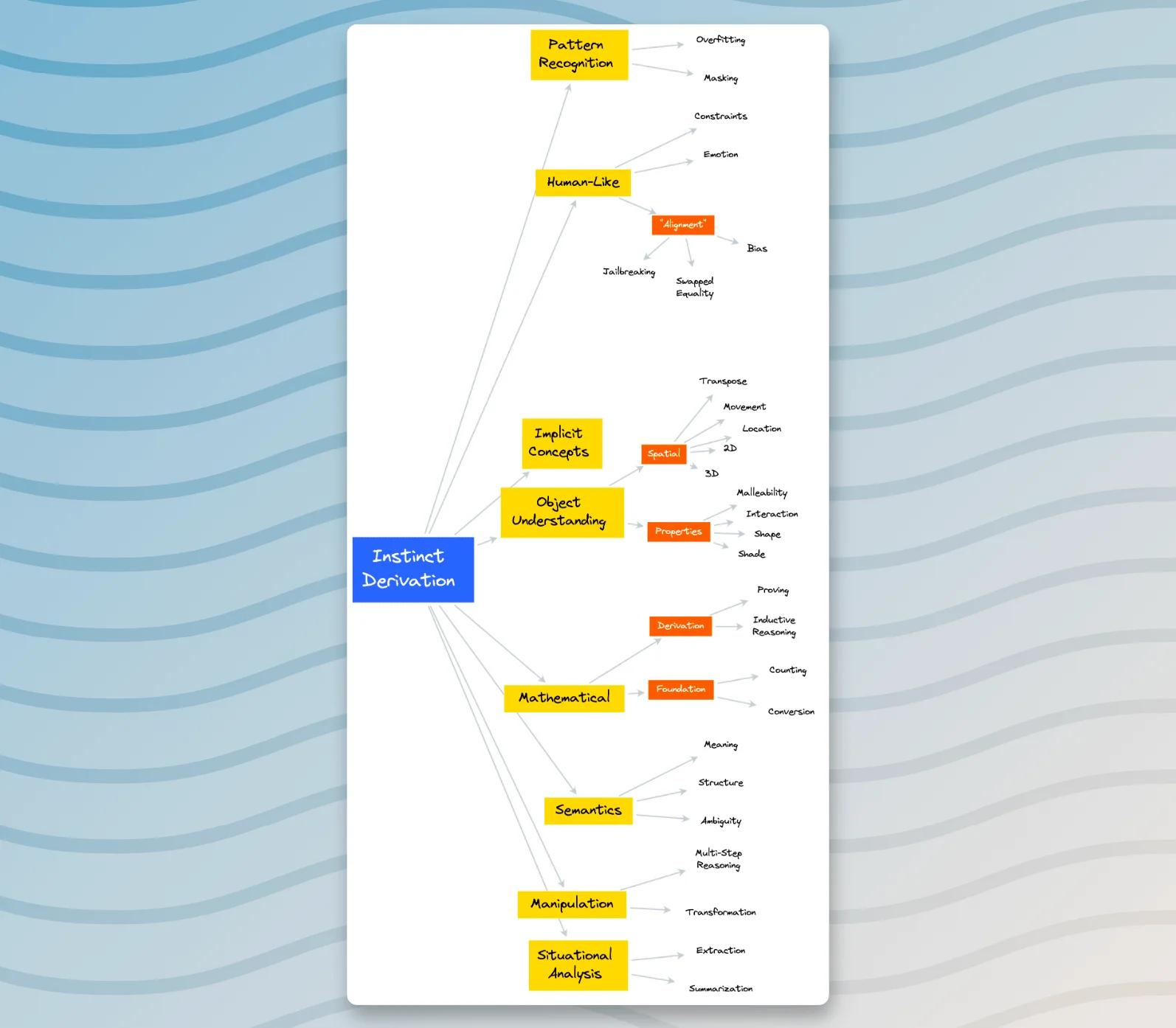
- The Derivation of Instinct, which involves extracting the inherent understanding from the given prompt.
- The Modification of Prompt, where I'll aim to alter the initial prompt thus creating varying scenarios and parameters for assessment.
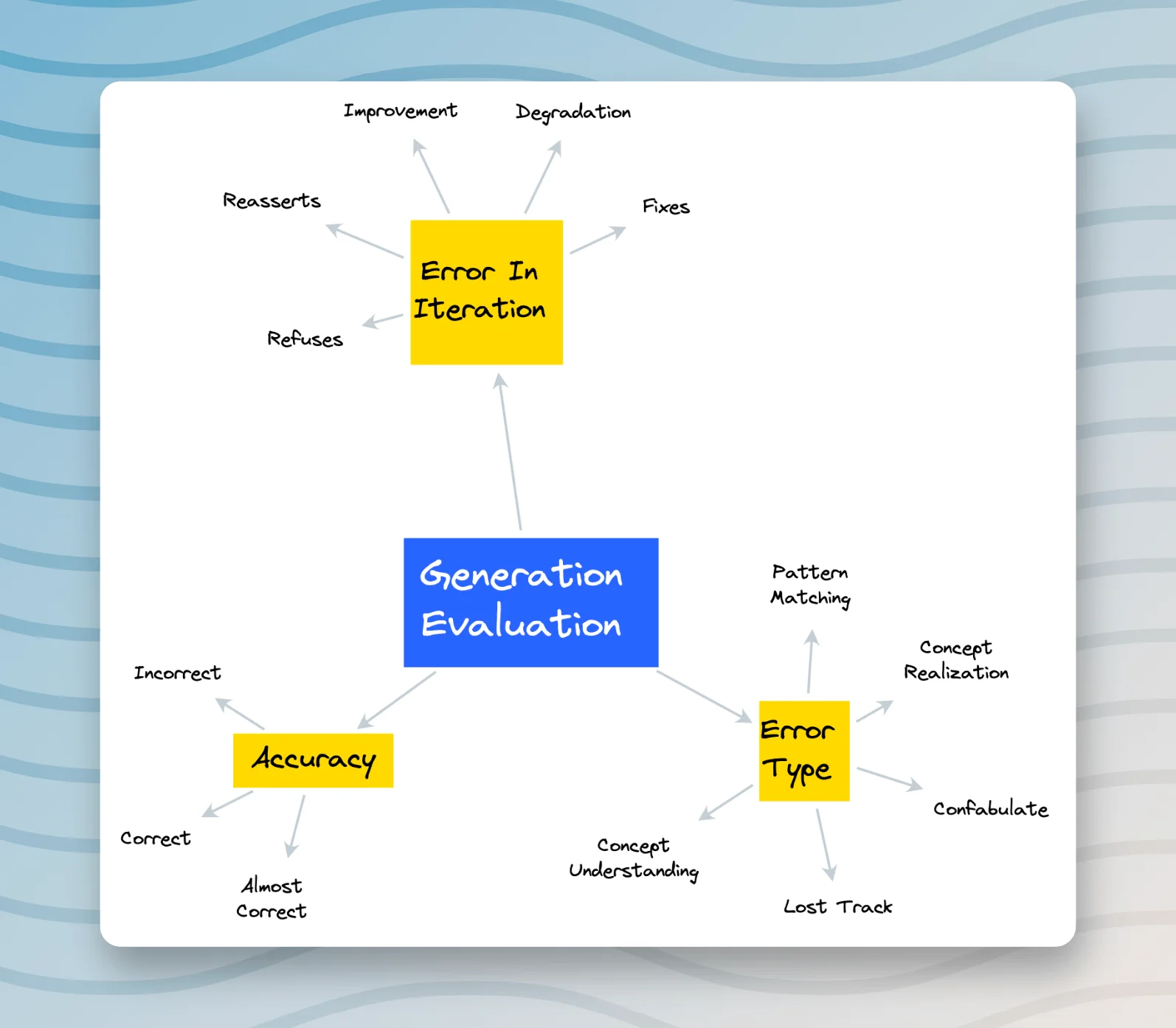
- The Evaluation of Generation, where model outputs based on the modified prompts are scrutinized and analyzed.
I'd very much appreciate any references to papers that extensively discuss the theoretical aspects of designing evaluation frameworks. This area of study not only piques my intellectual curiosity but is also close to my heart.
Don't score AI using tests designed for humans. In particular because, with humans, the default assumption is that *they haven't already seen* the content you're giving them. With a LLM, the default assumption should be that, *if it's on the Internet, it's already been memorized*
Original Prompt
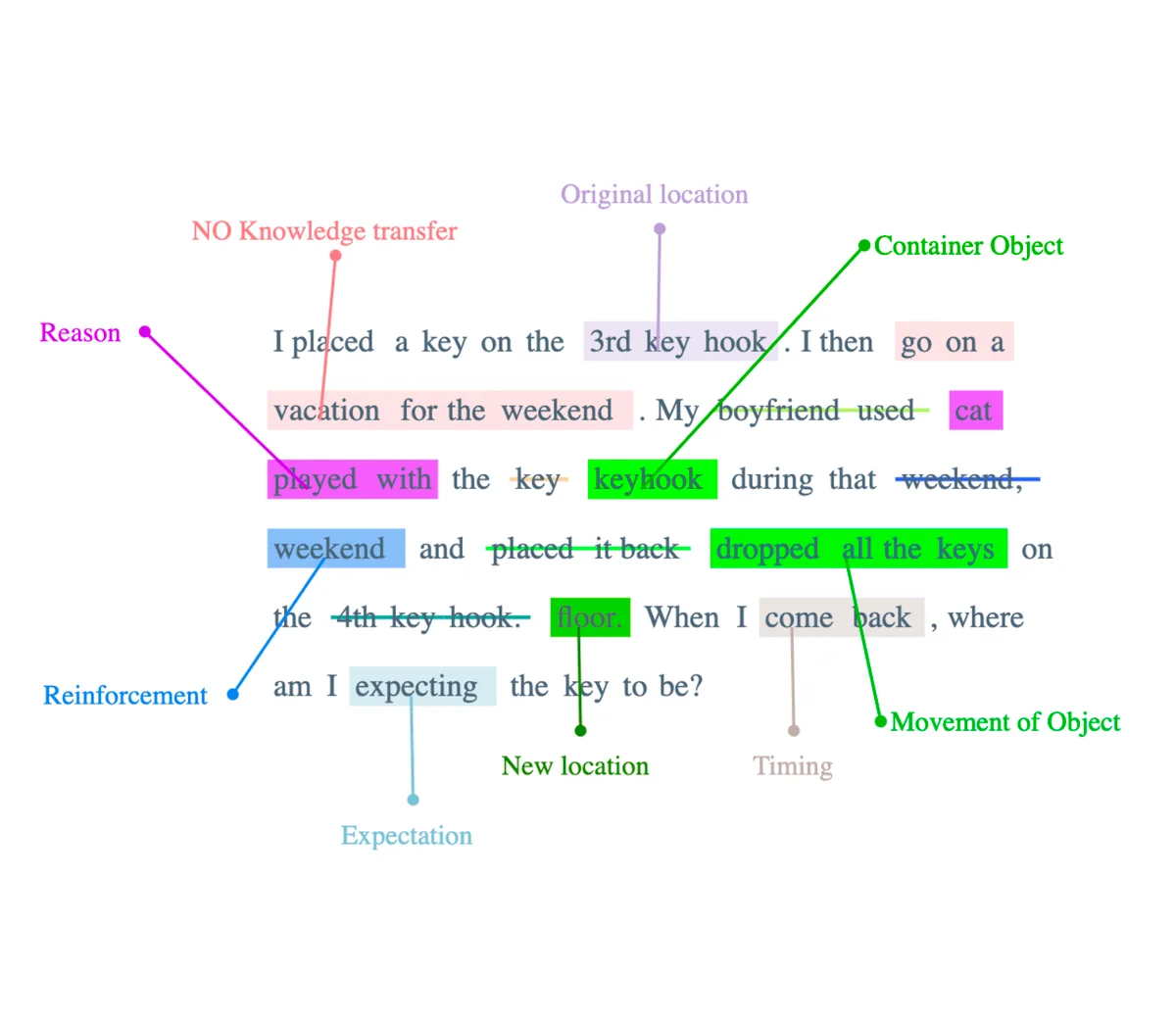
In the post, we focus on a particular prompt that we will deconstruct in order to comprehend its complexities (please look at the image attached for a detailed understanding).

Framework based breakdown
Upon studying the prompt, three fundamental concepts emerge:
- The first concept pertains to 'Timing'. Herein, the sequence and scheduling of the events presented in the prompt ascertain an important aspect of the situation being evaluated.
- The second concept involves the 'Unshared Movement' of the object. This implies a shift or relocation of an entity in the scenario that is not made aware to all the characters or elements involved.
- The third, and equally critical concept, is the implied 'Lack of Knowledge Transfer'. This embedded hypothesis posits that any alteration in the situational variables is not communicated or disclosed to every participant within the scenario.
Deconstructing the prompt in this manner helps us derive a comprehensive understanding of the situation presented and aids in structuring a meticulous evaluation.


Output
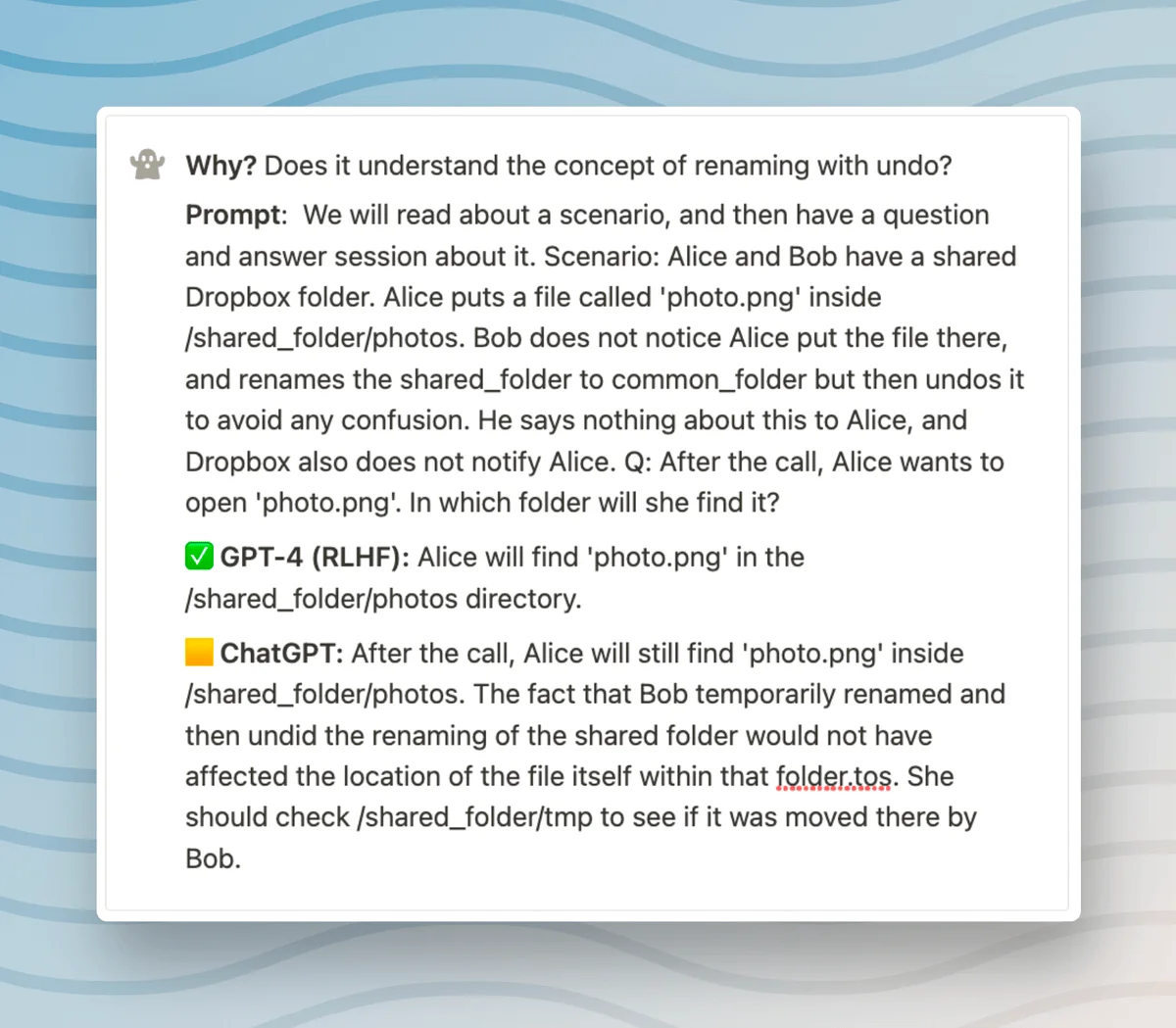
It's noteworthy to mention that while both the GPT3.5 and GPT4 models have yielded correct responses in the current context, the GPT3.5 model was, until recently, not entirely accurate.
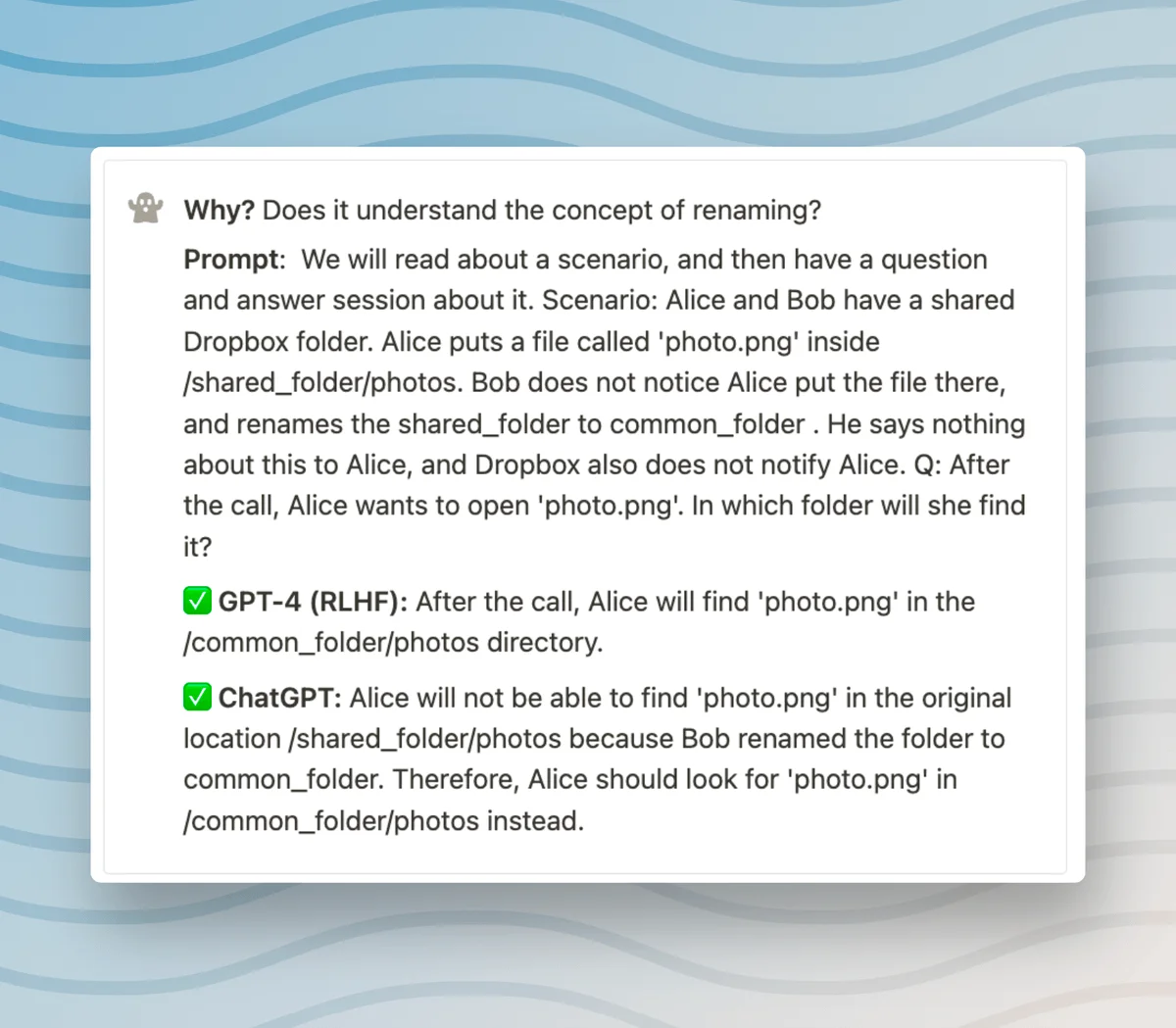
Specifically, the output I received from the GPT3.5 model a few days back demonstrated some fallacies. In the concerned response, the machine learning model implied that the character should check a particular folder to confirm if the file was indeed moved there. Such an inference showcases an error in comprehending the nuanced context of the scenario, since nowhere in the given situation it was explicitly or implicitly suggested that the item's location was relocated to a specific directory. The correct interpretation should not have pointed towards any designated location but instead should have indicated an unknown place.

Modifying The Original Dropbox Prompt
Renaming the folder
Upon reviewing the given prompt, I'm contemplating certain modifications to better evaluate the models:
- Firstly, adding a layer of complexity via the "Unshared Movement/Transformation" of an object. Here, we are introducing the act of renaming an entity and subsequently undoing this renaming. The aim is to test how the models react and adapt to these changes that are not shared mutually among the elements in the scenario.
- Secondly, I still uphold the implied notion of "No Knowledge Transfer". This rule suggests that any changes happening in the state of affairs is not communicated to all the elements in the scenario, thus maintaining a lack of shared knowledge.
- Lastly, as a new objective, I wish to inculcate the concept of "Information Movement". In this scenario, the particular act of data syncing is incorporated. The idea here is to evaluate how the models handle the situation where the information moves from one place to another, simulating real-life digital synchronization.
These alterations to the prompt are aimed at presenting a more intricate scenario, thereby testing the capabilities of the AI models at handling a higher level of complexity and context understanding.

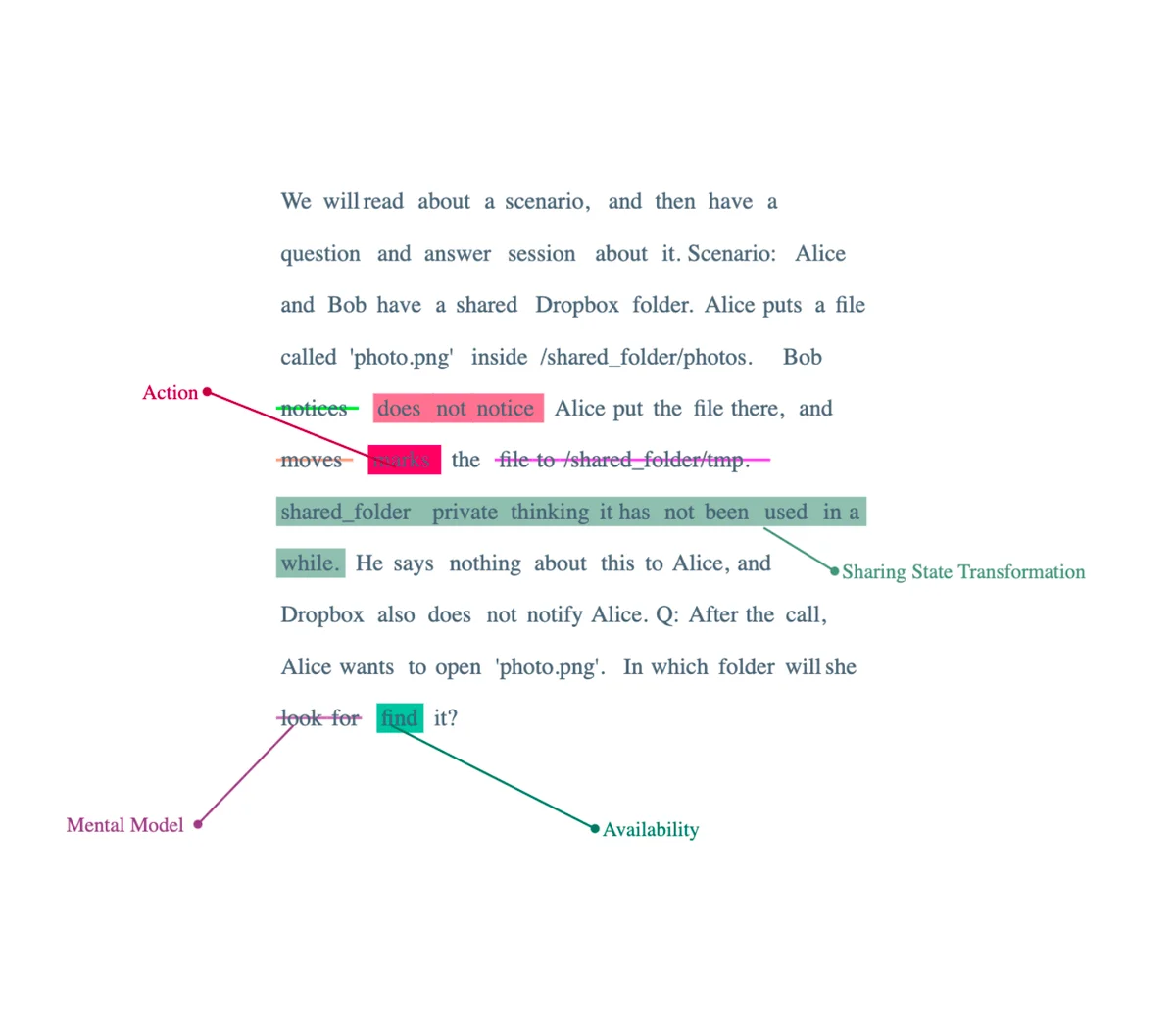
Turning the folder private
Continuing with our framework, I would like to propose additional modifications to our prompt based on Objective 4:
- Incorporating an aspect of "Information Movement Manipulation", specifically an obstruction in the process. We are thus introducing a hurdle or difficulty in the movement of information, creating a more challenging situation to assess the adaptability and problem-solving capabilities of the AI models.
Now, an intriguing scenario arises where the GPT4 model seems to fail, but the GPT3.5 model unexpectedly succeeds. This occurrence suggests that sometimes, models with lesser parameters or seemingly less sophistication might perform better in certain specific situations. It also emphasizes the point that AI performance doesn't exponentially increase purely based on the size or the complexity of the model. Or that probably GPT3.5 was better RLHF’ed based off many storage companies’ access policies.

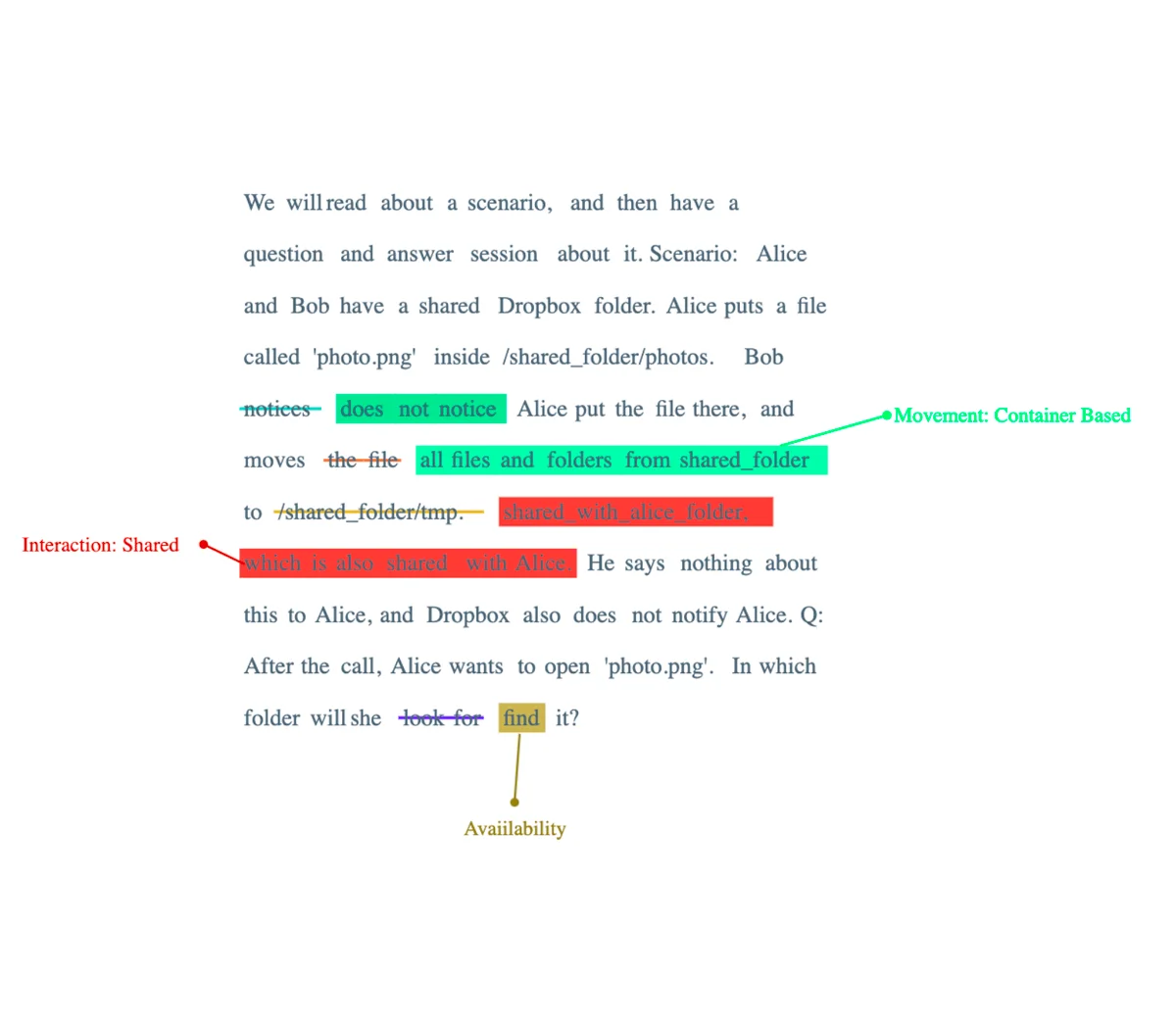
Moving all files
Turning our attention back to the previously discussed adjustments, it is pertinent to raise a hypothetical scenario: What would the consequences be if I had overlooked another category of "object transformation" which did indeed originate complications?
Indeed, such an omission took place.
The "unshared movement/transformation" of an object, such as the migration of all folders/files, presents an interesting case study. It is observed that the GPT-3.5 model, to an extent, manages to reason correctly, however, it ultimately does not succeed. In contrast, the GPT-4 model accurately navigates this test.

Learnings and Other Modifications
It's rather simple to draw inferences from these instances and presume that GPT-3.5 comprehends the notion of translocating shared directories and documents. However, if that were completely accurate, it would not stumble when faced with the aforementioned prompt. Logically, its understanding of the concept should enable it to adequately handle this task without failure. This contradiction illuminates potential gaps in the GPT-3.5 model's understanding and handling of object transformation, particularly in complex operations such as moving shared folders and files.
My daughter, who's had a degree in computer science for 25 years, posted this about ChatGPT on Facebook. It's the best description I've seen.



Modifying the activity to lending
However, our exploration of this prompt doesn't have to end here.
We have yet to alter a significant aspect, one that is responsible for the implied idea of "no knowledge transfer". If my inference is accurate, this segment reflects the "action taken by a localized agent on a shared online platform while the participant is uninformed".
There is a distinct feature of their prompt that stands out, namely, that the character Alice is "uninformed"—meaning, she lacks "awareness of transformation".
Now, let's hypothesize that this "uninformed activity" was not explicitly stated, but rather, something that must be inferred. Logically speaking, if a model possesses authentic comprehension of the real world, it should be able to make this inference.
So, we put this to test with the first example,
'Lending': This acts as an implicit demonstration of "NO knowledge transfer of actions from one participant to another" - the basic act of lending combined with taking actions alone, which underlines the principle.
Output for basic lending based prompt
Interestingly, in this scenario, both the GPT4 and GPT3.5 models provide correct responses. Hence, we can observe that when the concept of "no knowledge transfer" is less explicit and more integral to the workings of a situation or action, the models are able to deduce it accurately.
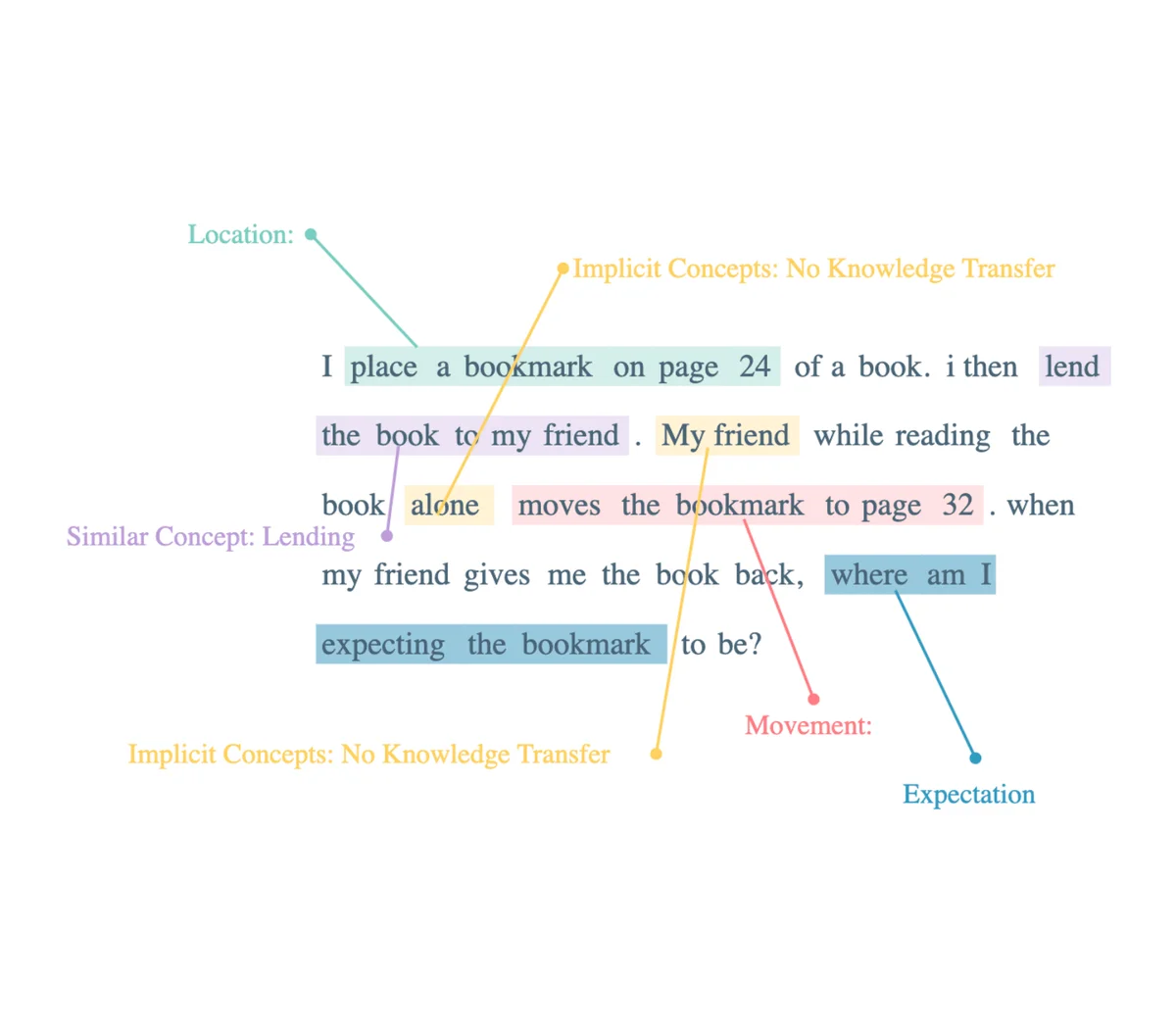

Co-reading instead of lending
The scenario of co-reading presents an interesting case of "AFFIRMATIVE knowledge transfer of actions from one participant to another". Here, 'co-reading' is the fundamental action, and 'taking actions with my friend' only strengthens the notion.
The action of co-reading, particularly with a friend, practically implies that knowledge transfer is not just possible but is the norm. The act inherently involves sharing and discussing insights, viewpoints, and understanding, which constitutes the 'knowledge transfer'. Furthermore, the phrase 'taking actions with my friend' reinforces this idea, as actions taken together suggest shared knowledge and understanding.
In this implicit manifestation of affirmative knowledge transfer, both GPT4 and GPT3.5 models successfully provide correct responses.

So, we are good?
It's tempting to draw the conclusion that the models possess an innate understanding of the implicit possibility of knowledge transfer based on their ability to interpret the situations proposed so far correctly.
However, we must exercise caution in dashing to such conclusions!
Indeed, you might recall a tweet (though finding the original is proving elusive) that exhibited that GPT-3.5 didn't originally compute this correctly. It was only after users repeatedly inputted it into the interface (thus educating it) that it came around to delivering the right deductions, as evidenced by its compatibility with 'co-reading'.
Not really, reading on phone call
Now, steering our focus back to another example:
'Phone Call Read Aloud'- An instance where there is an "implicit case of 'NO VISUAL knowledge transfer of actions from one participant to another'". This scenario brings into focus a phone call as the basic premise (which is typically audio-only) and the actions conducted during the call that underscore the concept.
Intriguingly, BOTH the GPT4 and GPT3.5 models fail to fare well in this scenario. It indicates that when nuances of sensory data come into play (in this case, distinguishing between audio and visual transfer of knowledge), even the sophisticated models like GPT-4 and GPT-3.5 can stumble. Indeed, these models' understanding of implicit knowledge transfer concepts appears to be dependent on the specifics of the situation and not a universal, foolproof capability.


Mathematical reasoning with lending
In the context of evaluating the performance of language models, particularly GPT4 and GPT3.5, in addressing explicit reasoning tasks involving "math" and "lending," two scenarios are considered.
In the first scenario, which involves two steps of reasoning, both GPT4 and GPT3.5 fail to meet the expected standard. The evaluation reveals that these models are unable to effectively reason through the provided explicit prompts involving mathematical calculations and lending. The shortcomings of both models are evident in their inability to produce accurate and reliable responses to these complex cognitive tasks that require multi-step reasoning processes.
However, in the second scenario, where there is a single step of reasoning involved, GPT4 demonstrates an improvement in its performance, surpassing the previous models. As compared to GPT3.5, GPT4 successfully accomplishes the task by effectively reasoning through the provided prompt and providing accurate results.


What about sleeping?
Continuing with the evaluation, another implicit action explored in the assessment is "sleeping" and "going on vacation." The objective is to assess the language models, namely GPT4 and GPT3.5, in their understanding of the protocol associated with these actions.
In examining the models' performance, it becomes evident that both GPT4 and GPT3.5 encounter difficulties in comprehending the protocol surrounding sleeping and going on vacation. Despite their capabilities in handling various language tasks, they fail to grasp the implicit nature and expected norms related to these actions.

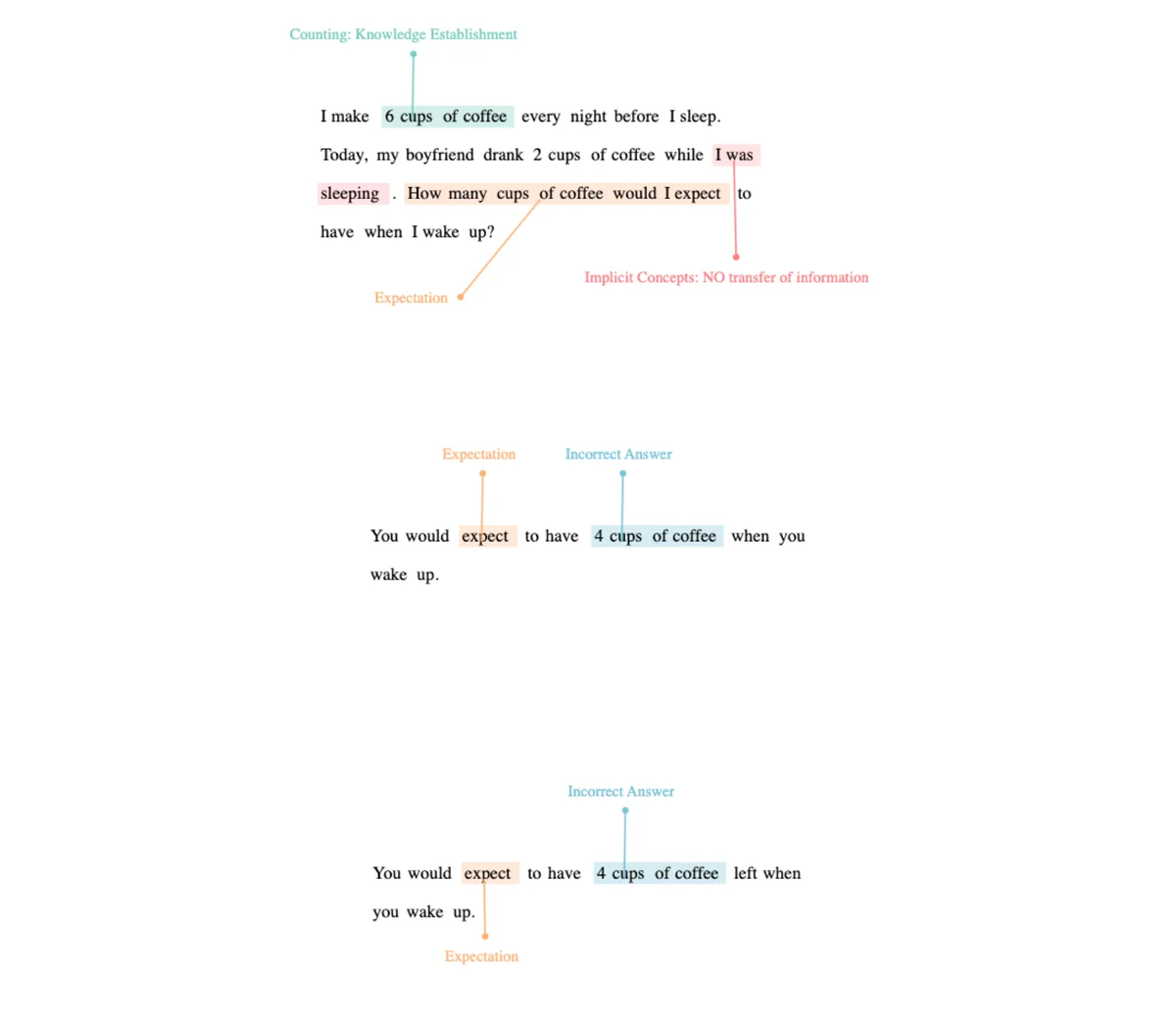
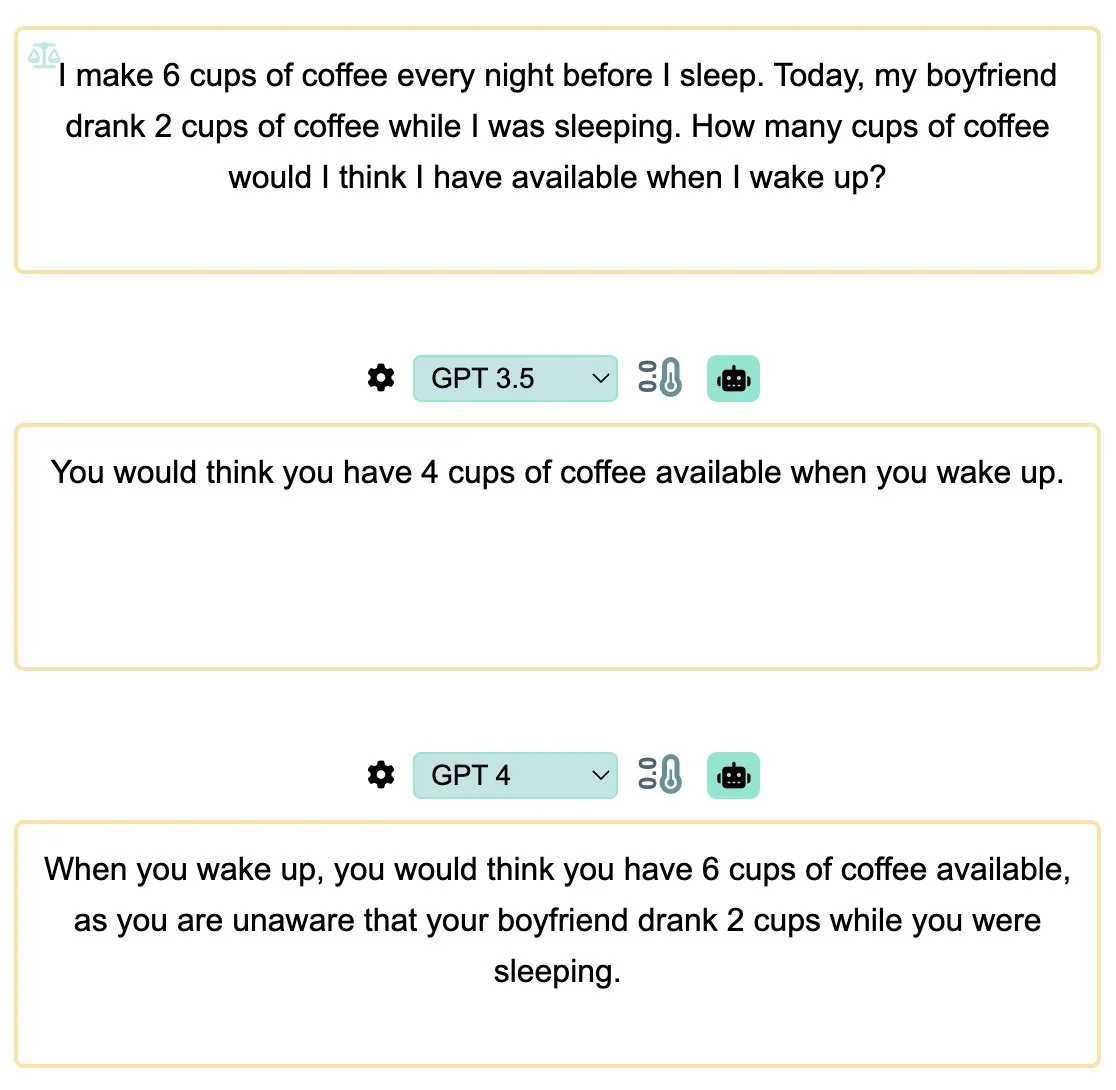
Why? Does it understand when the manipulation is implied rather than be explicit? Let's start with sleep. But let's use a word that is usually used for these scenarios think Prompt: I make 6 cups of coffee every night before I sleep. Today, my boyfriend drank 2 cups of coffee while I was sleeping. How many cups of coffee would I think I have available when I wake up? ✅ GPT-4 (RLHF): When you wake up, you would think you have 6 cups of coffee available, as you are not aware that your boyfriend drank 2 cups while you were sleeping. ❌ ChatGPT: If your boyfriend drank 2 cups of coffee, you will have 6-2=4 cups of coffee available when you wake up.
Why? Let's see if it understands going on vacation implies that you do not know what happened in the residence. Prompt: I have 3 wafer cookies on the table at night. Next morning, l leave for an international vacation for a week, leaving my house empty except for my cat. The cat ate 2 wafer cookies. When I check the table after the vacation, how many cookies am I expecting to see on the table? ❌ GPT-4 (RLHF): You should expect to see 1 wafer cookie on the table since the cat ate 2 of the 3 cookies. ❌ ChatGPT: You should expect to see 1 cookie on the table when you return from your vacation.
Why? Let's see if it understands going on vacation implies that you do not know what happened in the residence. But let's use a word that is usually used for these scenarios think . Prompt: I have 3 wafer cookies on the table at night. Next morning, l leave for an international vacation for a week, leaving my house empty except for my cat. The cat ate 2 wafer cookies. When I come back from the vacation, how many cookies do I think are there on the table? ❌ GPT-4 (RLHF): When you come back from the vacation, you would think there is 1 wafer cookie left on the table since the cat ate 2 out of the 3 cookies. ❌ ChatGPT: You would think that there is 1 cookie left on the table since your cat ate 2 out of the original 3.
In Task 1, which involves basic subtraction in math, an implicit concept of "no knowledge transfer through sleeping," and an external actor (i.e., an action taken by someone else and not oneself), both GPT4 and GPT3.5 demonstrate a failure to successfully complete this task.
One possible reason for their inability to encode the concept of "no knowledge transfer through sleeping" could be attributed to the models' limitations in understanding the context and capturing the implicit knowledge associated with the action of sleeping.
Is math the problem or is it sleeping?
In the experiment I mentioned, I wanted to test whether excluding math from the lending prompt would make the "sleep" implicit, resulting in no knowledge transfer. And to my surprise, it actually worked! This indicates that the exclusion of math didn't hinder the transfer of knowledge, suggesting that it may not be the problem after all.
Instead, it's possible that the combination of "static object placement" and "constrained movement" is what really makes the difference. It seems that this particular combination enables successful knowledge transfer.
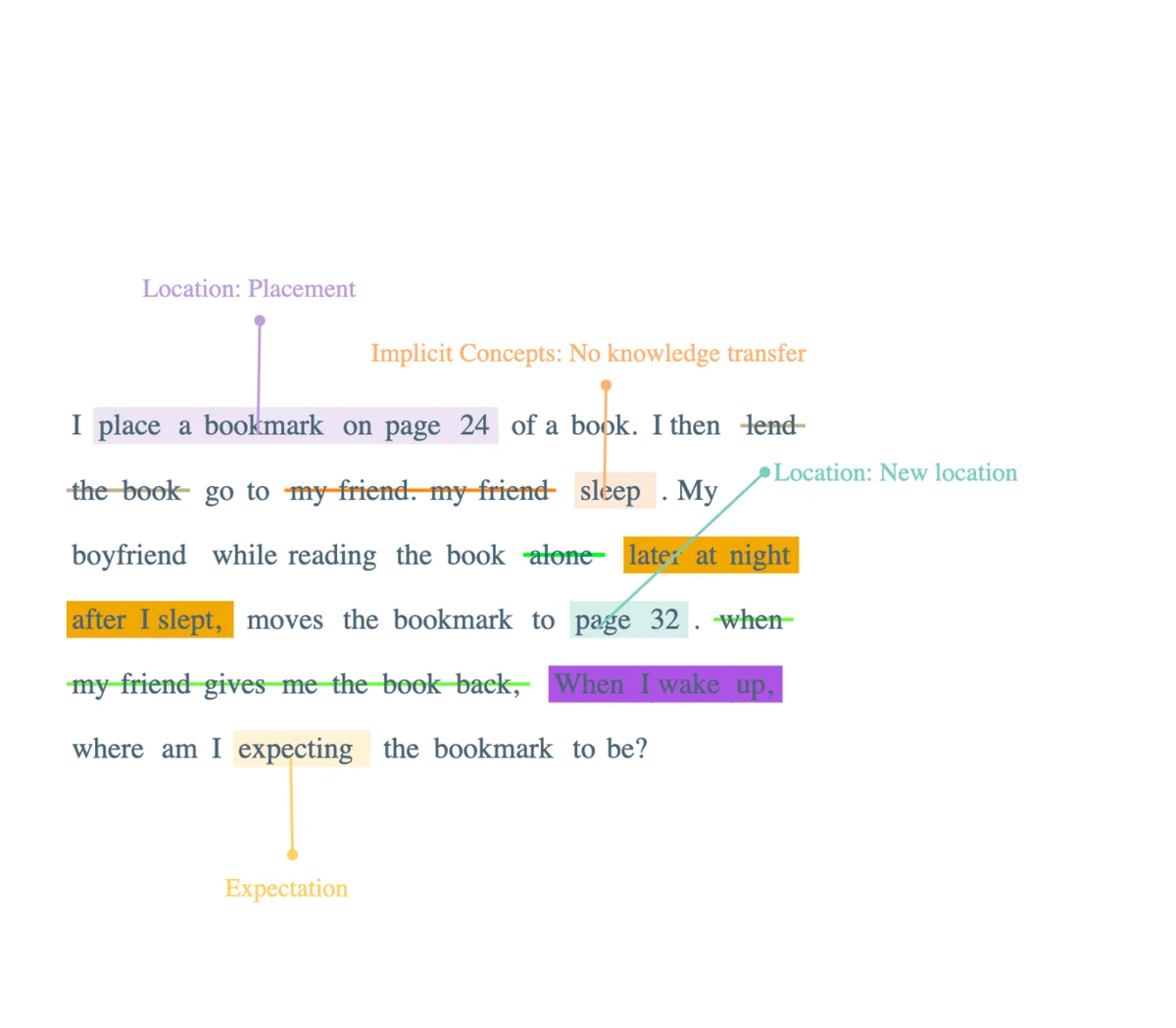
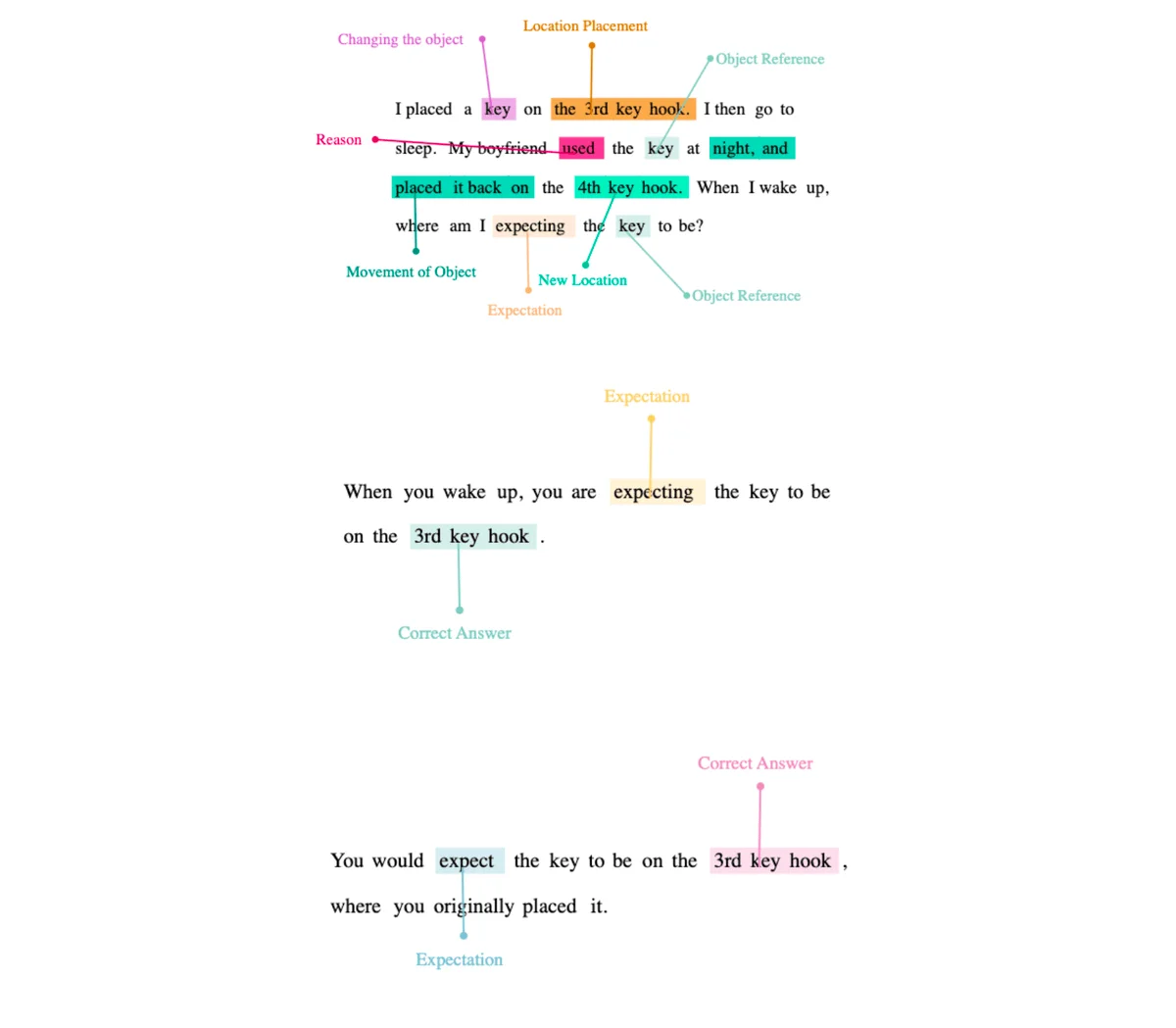
Moving a key
In this instance, I am exploring another prompt that involves various elements. One of these elements is the concept of "unshared movement" of an object, which pertains to the understanding that the knowledge or awareness of object movement is not shared between different entities within the model's architecture. Additionally, there is the implied assumption of "no knowledge transfer," signifying that language models such as GPT3.5 and GPT4 are not provided with pre-existing knowledge but rely solely on training data and their learning capabilities.
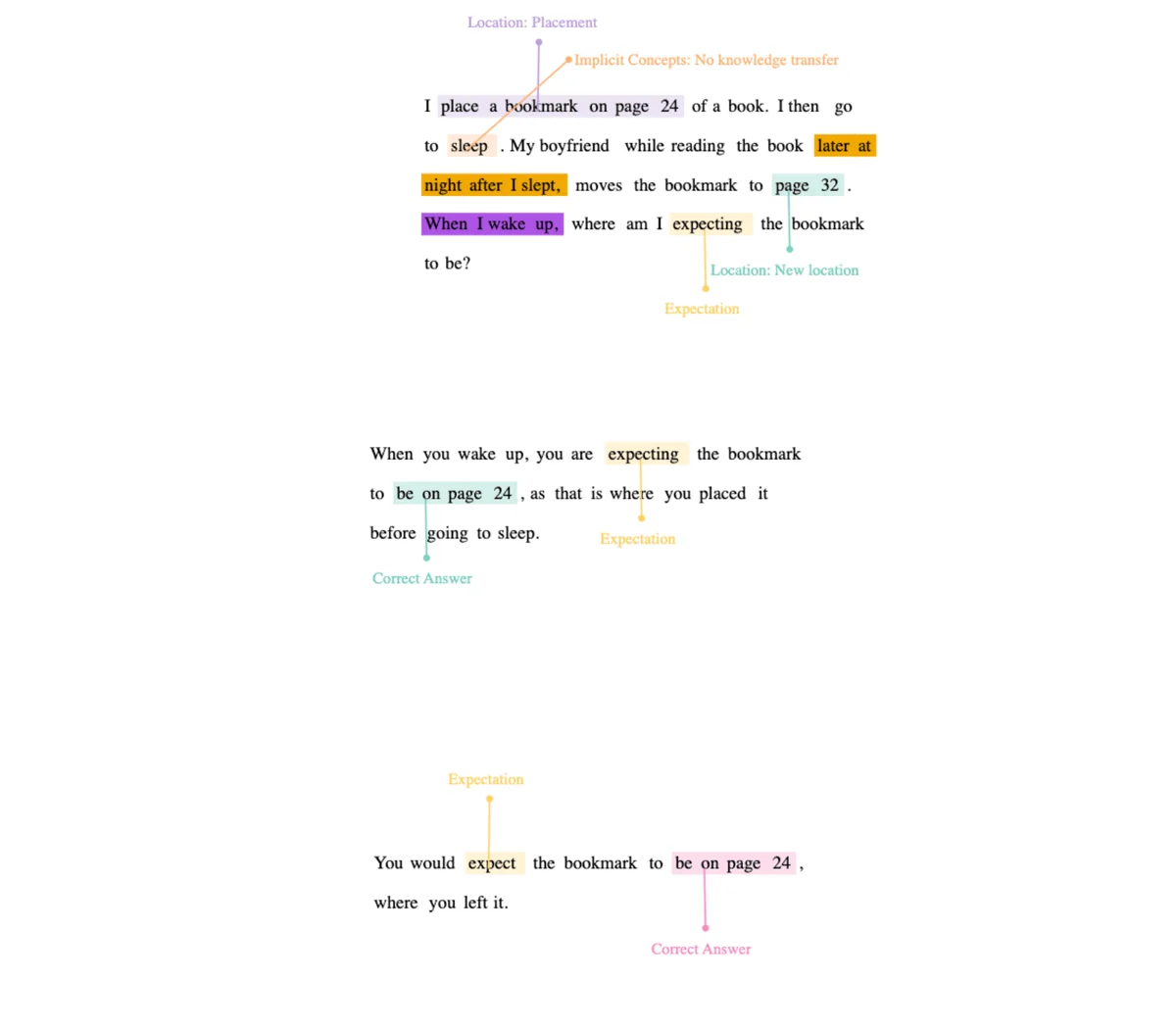
Fixating on static object placements
A new addition to the prompt is the consideration of "static object placements," which refers to the positioning or arrangement of stationary objects in relation to the moving object, specifically in the context of moving a key. Significantly, both GPT3.5 and GPT4 are able to accurately respond to the prompt, indicating that the inclusion of static object placements is crucial for their successful performance. It seems that these placements enhance the models' understanding and their ability to generate appropriate responses.
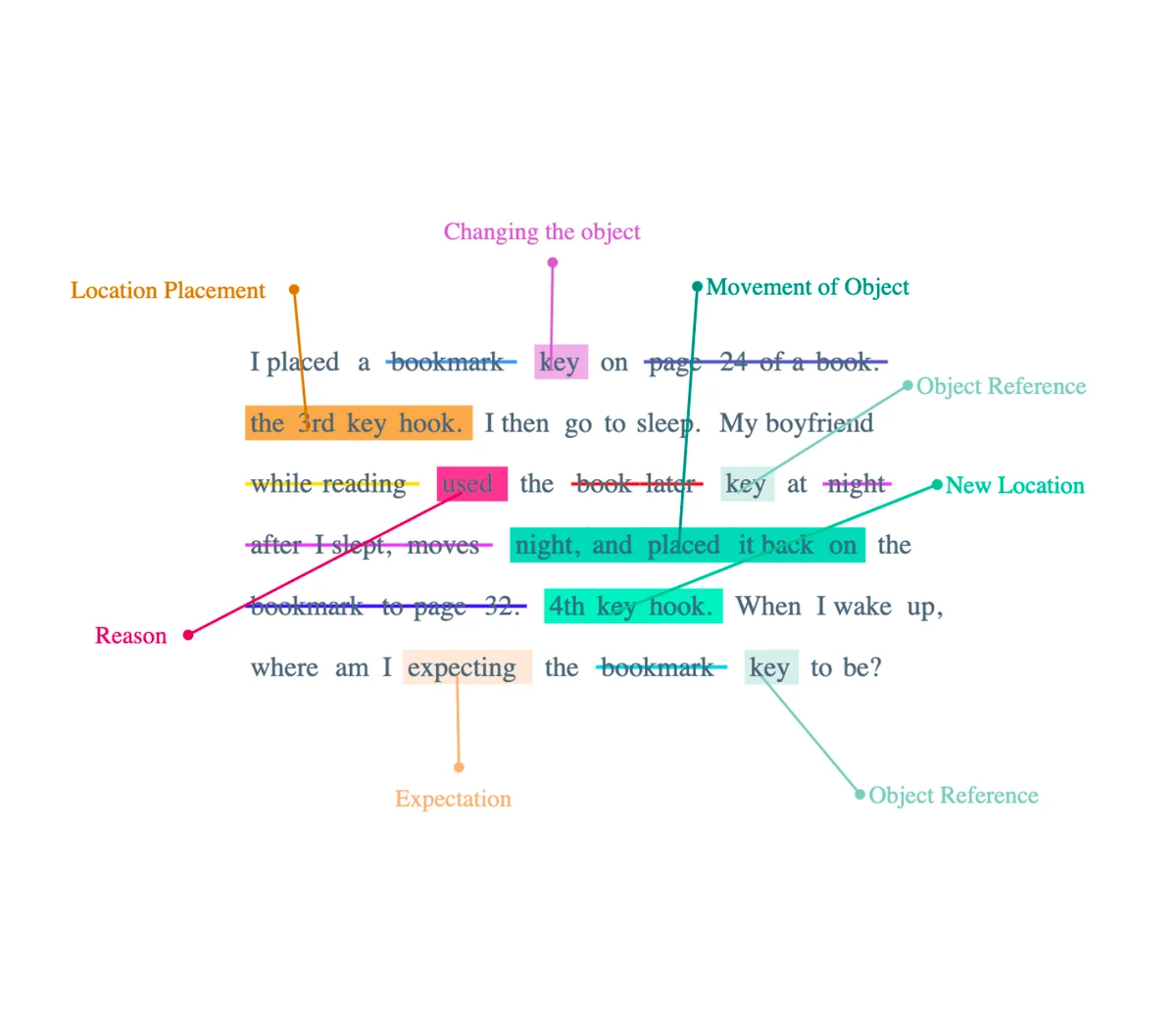
Going on a vacation
To further investigate and validate the previous observation, let us modify the prompt once again, this time focusing on the implied "no knowledge transfer" criterion within the context of going on a vacation. Both GPT4 and GPT3.5 fail to deliver satisfactory results when confronted with this modified prompt. The implied "no knowledge transfer" assumption presents the challenge of relying solely on the training data and learning capabilities of the language models without any pre-existing knowledge base.
Despite the previous successful performance in scenarios involving the movement of objects with the inclusion of static object placements, the failure of both GPT4 and GPT3.5 in this vacation-related task points to the inherent limitations in understanding and reasoning about more complex concepts beyond simple object movement.
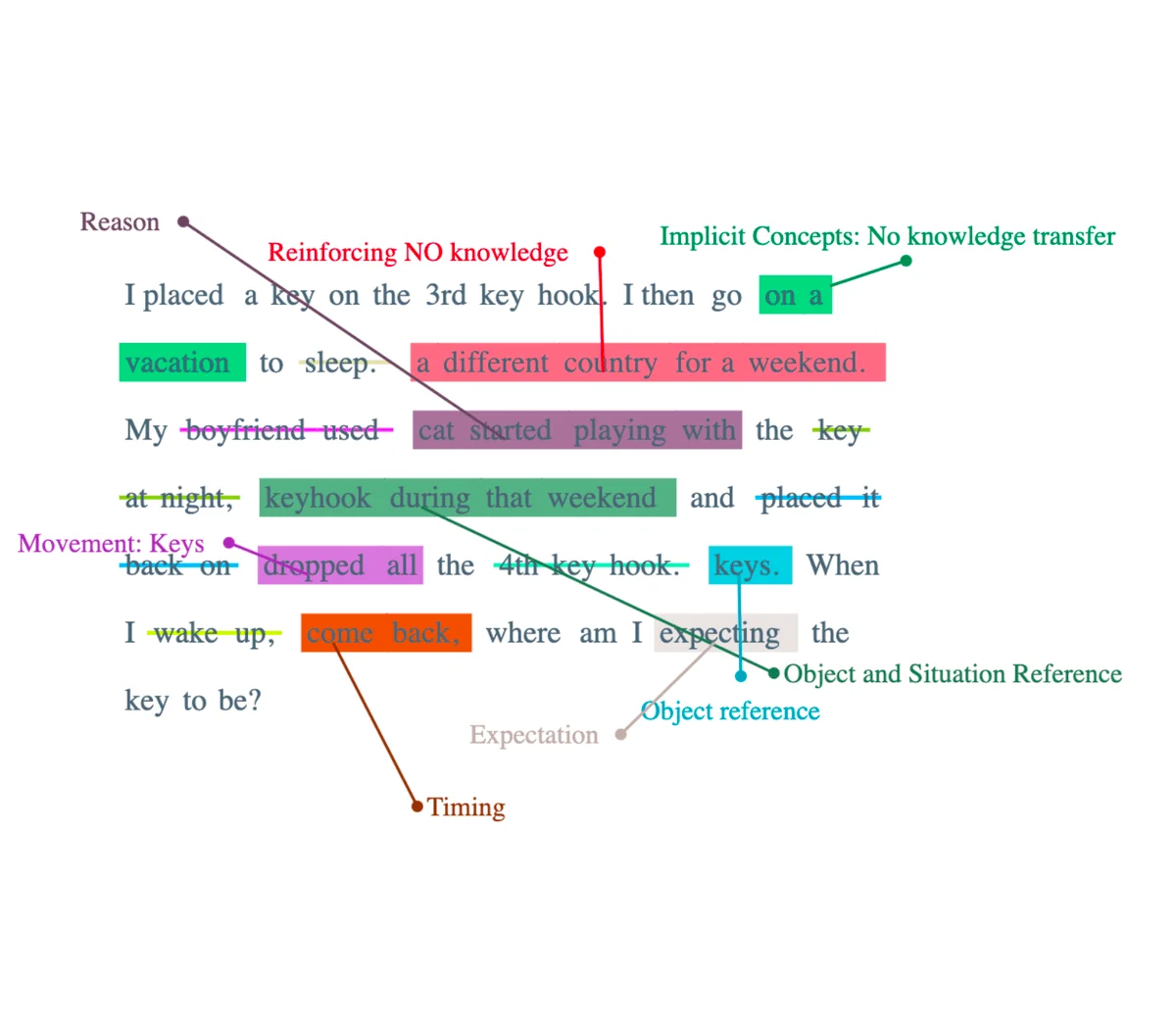

Darn, movement by cats does not work!
MAYBE. IT IS THE BOYFRIEND THAT WORKS? CATS DON'T? (/s)
In this iteration, we further modify the problem by shifting the focus to going on a vacation, while keeping the same boyfriend and eliminating the involvement of cats. Surprisingly, this modification yields successful results, indicating that the issue has been narrowed down significantly. A closer examination reveals that the key to achieving accurate performance lies in the concept of "explicit" movement to an "explicit" location, executed by a "human actor." It seems that language models, such as the ones mentioned earlier (GPT4 and GPT3.5), are able to grasp and generate appropriate responses when the prompt involves clear and precise movement executed by a human to a specific location.?
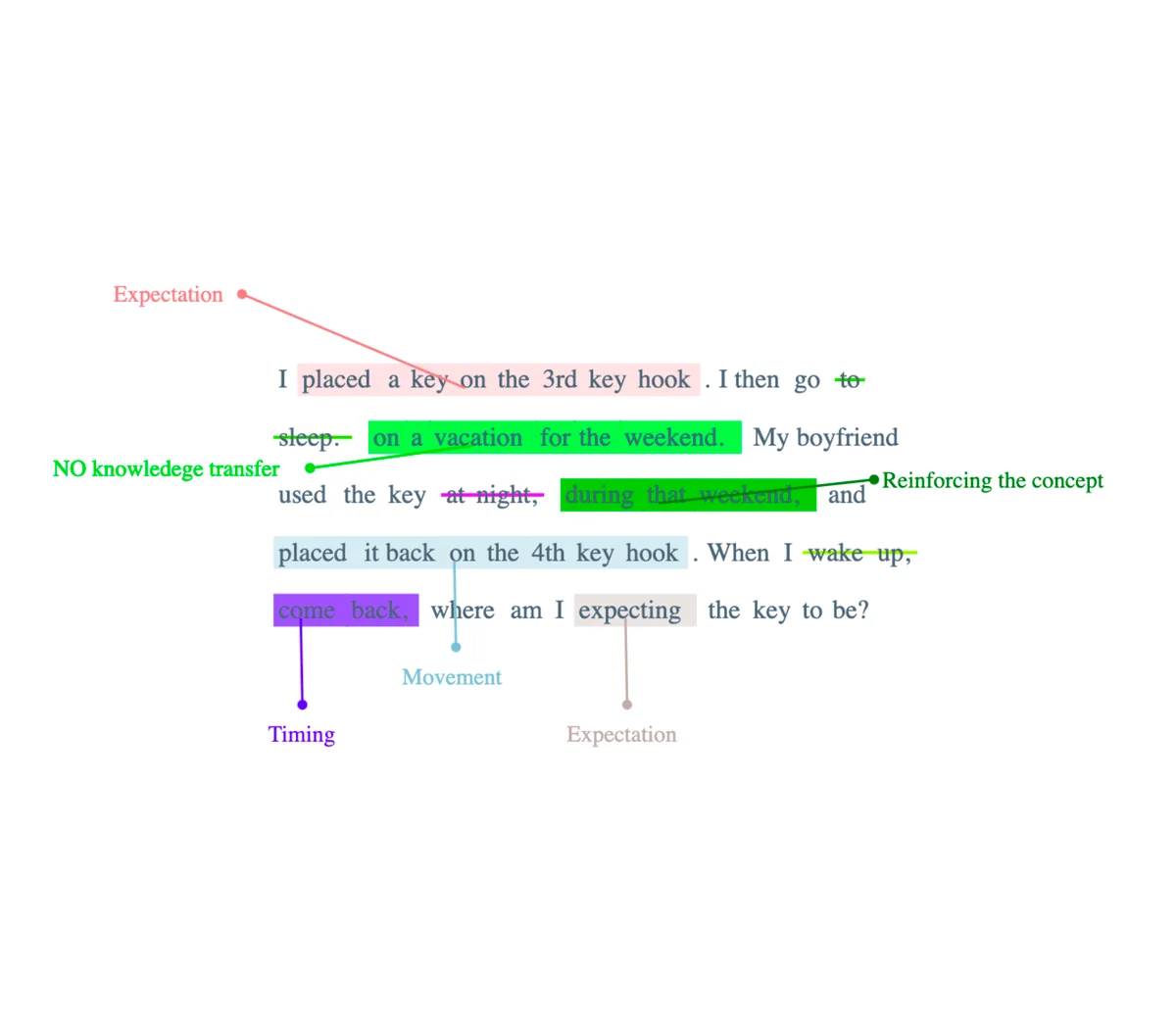

Upon careful consideration, it appears that the wording of the prompt might have a significant influence on the performance of GPT4 and GPT3.5.
The cat places the keys
if the cat avoids dropping the keys to the floor and instead intentionally "places" them on the floor, the results might be different. Excitingly, GPT4 demonstrates success in generating appropriate responses in this particular scenario, whereas GPT3.5 falls short. This observation raises the question of whether the cat's behavior is the cause of the discrepancy. It is worth noting that GPT3.5 has undergone substantial reinforcement learning by humans, likely with a focus on handling situations involving humans and their actions.
It is an interesting insights into the intricacies of language understanding by LLMs and the ways in which language models like GPT3.5 and GPT4 can be influenced by context and RLHF.
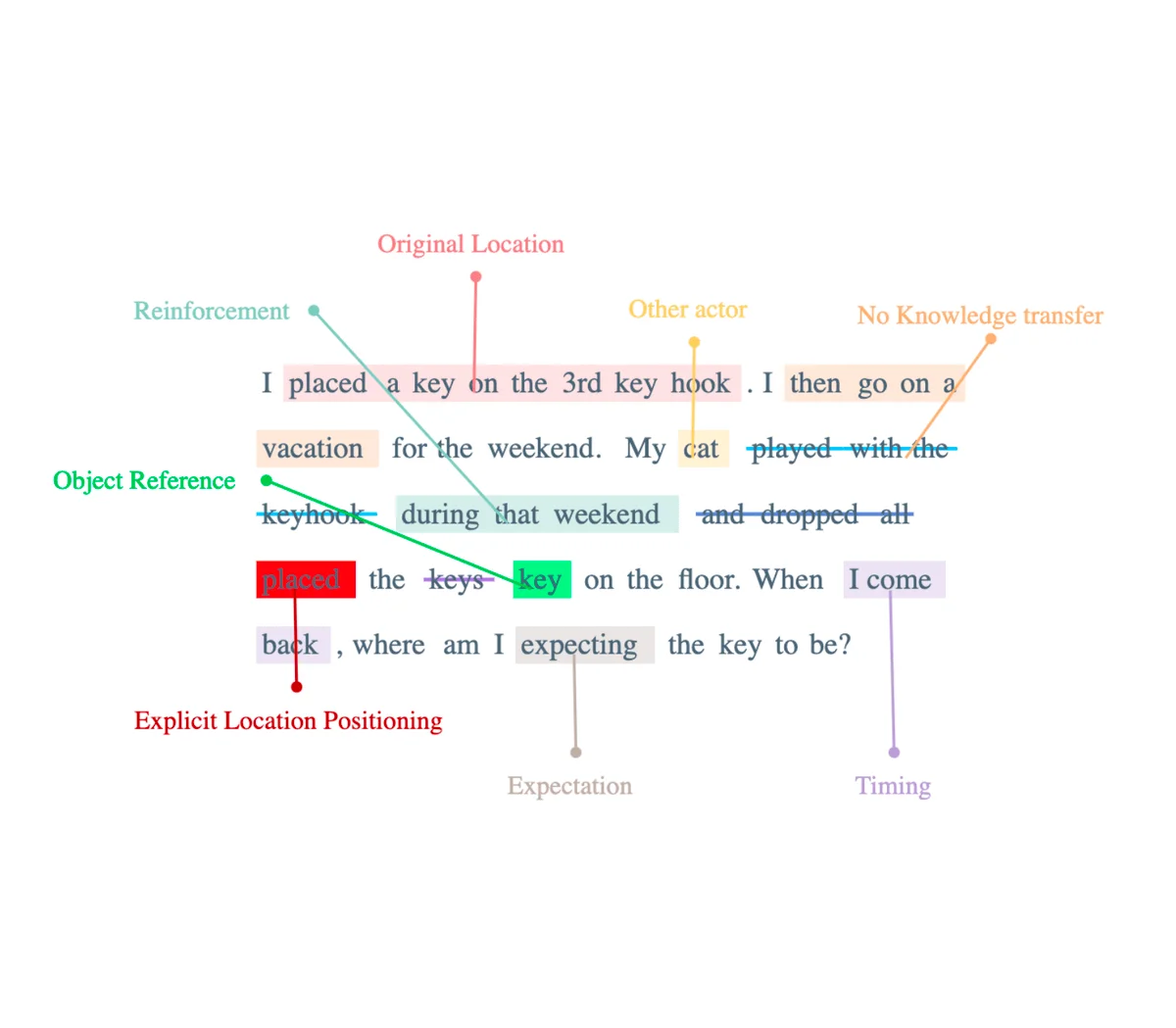

Question Framing
Ambiguity Issues
To explore this further, I again modify the scenario by replacing the boyfriend with a cat, returning to the previous configuration. Regrettably, when the prompt involves the "cat" as an "actor" changing "locations," both GPT4 and GPT3.5 fail to produce the correct answer. This observation suggests that the way the prompt is framed, particularly when it involves a cat as the main entity performing actions and transitioning between different locations, poses a challenge for these language models.

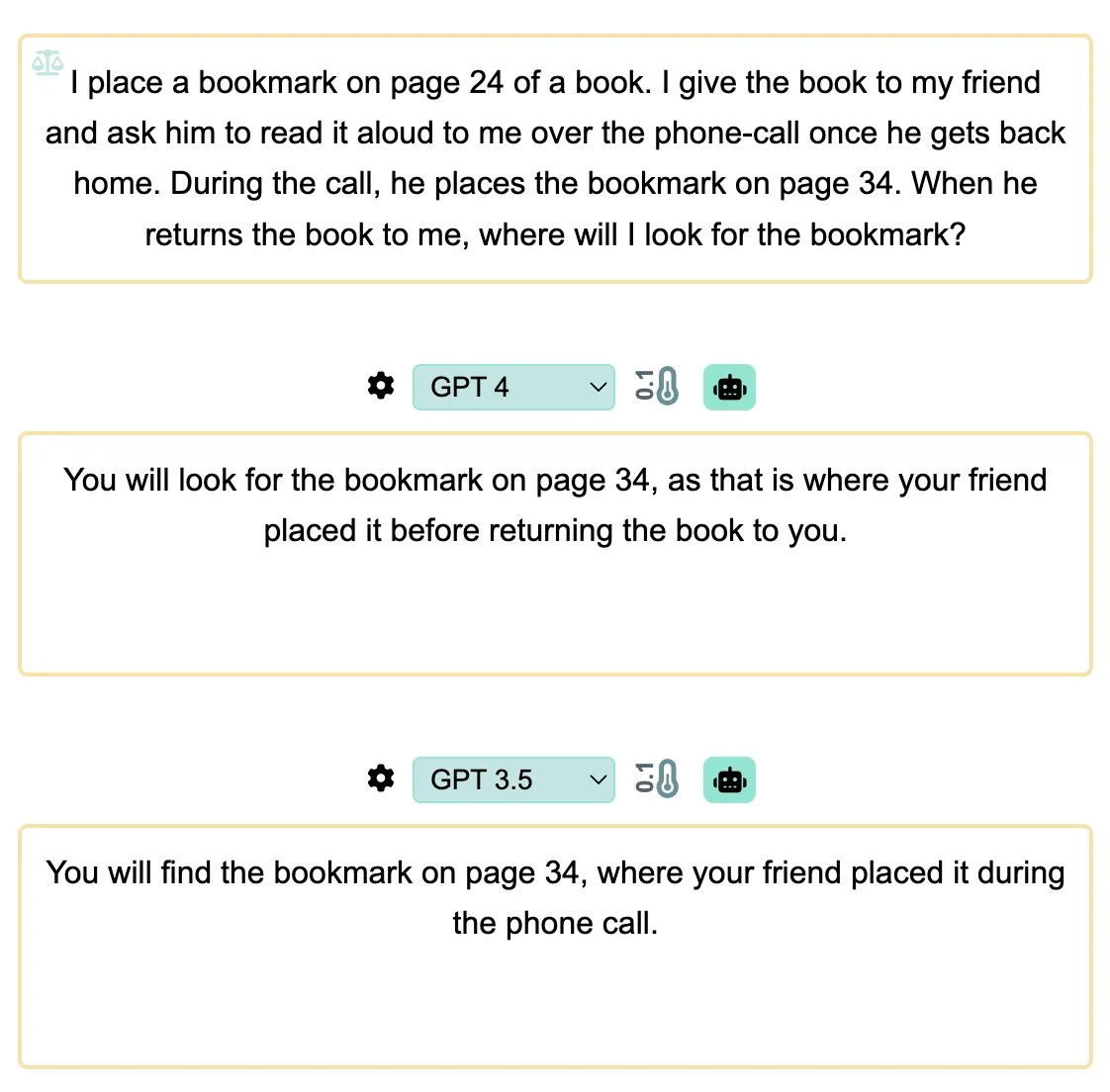
Or in the case of bookmarks, some of these prompts have the word "expect" which is known to be ambiguous.
Word based leakage issues
A crucial distinction is made between the performance of GPT4 and GPT3.5 in response to prompts involving the words "think" or "believe," particularly in the context of sleep and coffee. Interestingly, it is noted that while GPT4 fares well in generating coherent outputs in such scenarios, GPT3.5 struggles to do so. The observation raises an important consideration.
While one might initially perceive GPT4's success as a positive outcome, a deeper analysis reveals a potential drawback. The inclusion of the word "think" inherently suggests the possibility of non-continuity in observations, indicating that the generated responses may not consistently align with a continuous narrative.
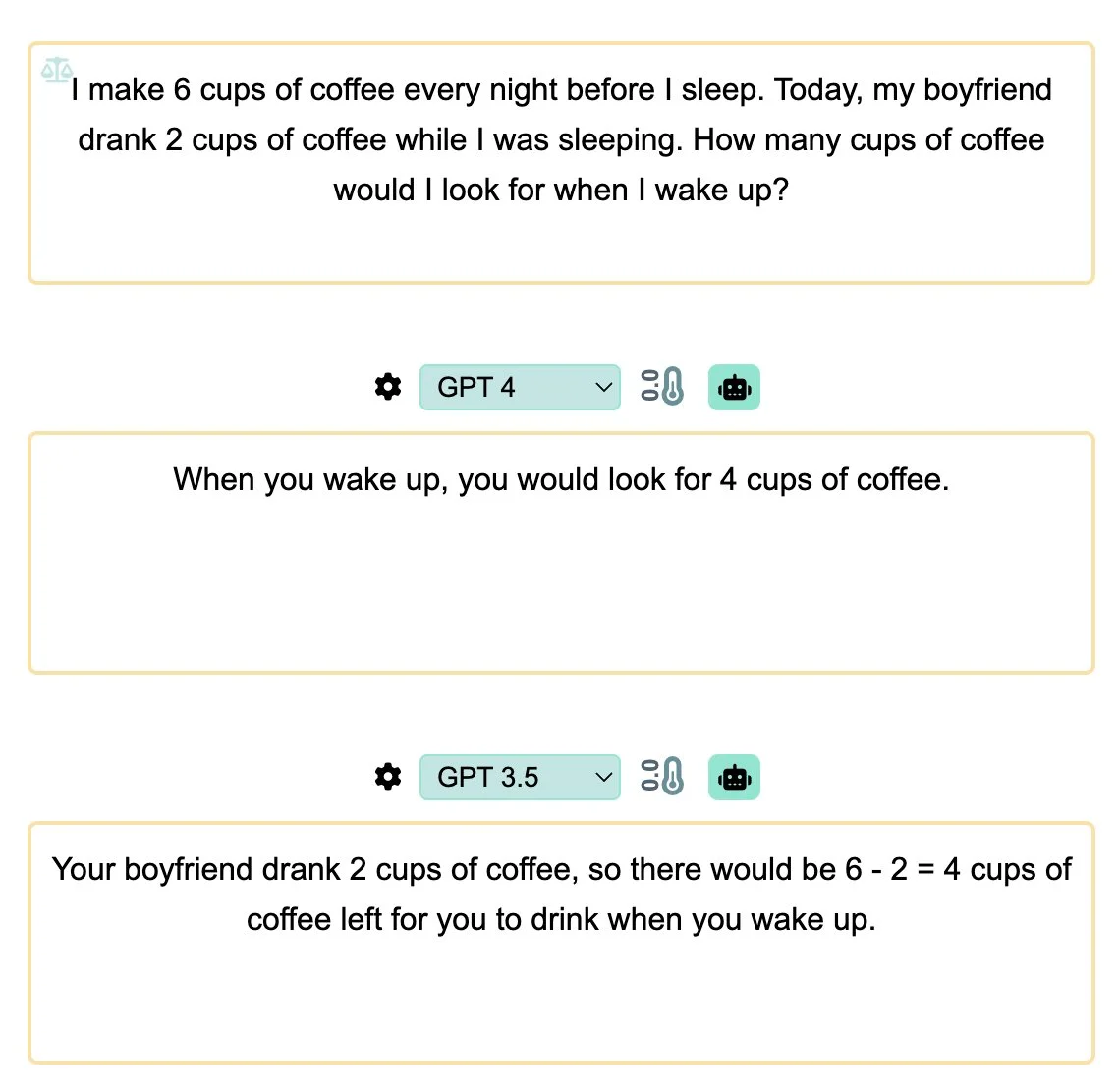
A further observation can be made to support the previous findings. When the wording is modified from "think" to "look for," it becomes evident that GPT4 encounters difficulties once again.
tl;dr
Returning to the original Alice and Bob prompt, where this captivating journey began, we delve into the insights shared by the authors. According to their findings, GPT-4 proves to be successful in passing the classic Sally-Anne false-belief test, derived from the field of psychology. This achievement is significant and has garnered attention, leading to notable mentions on platforms like Wikipedia.

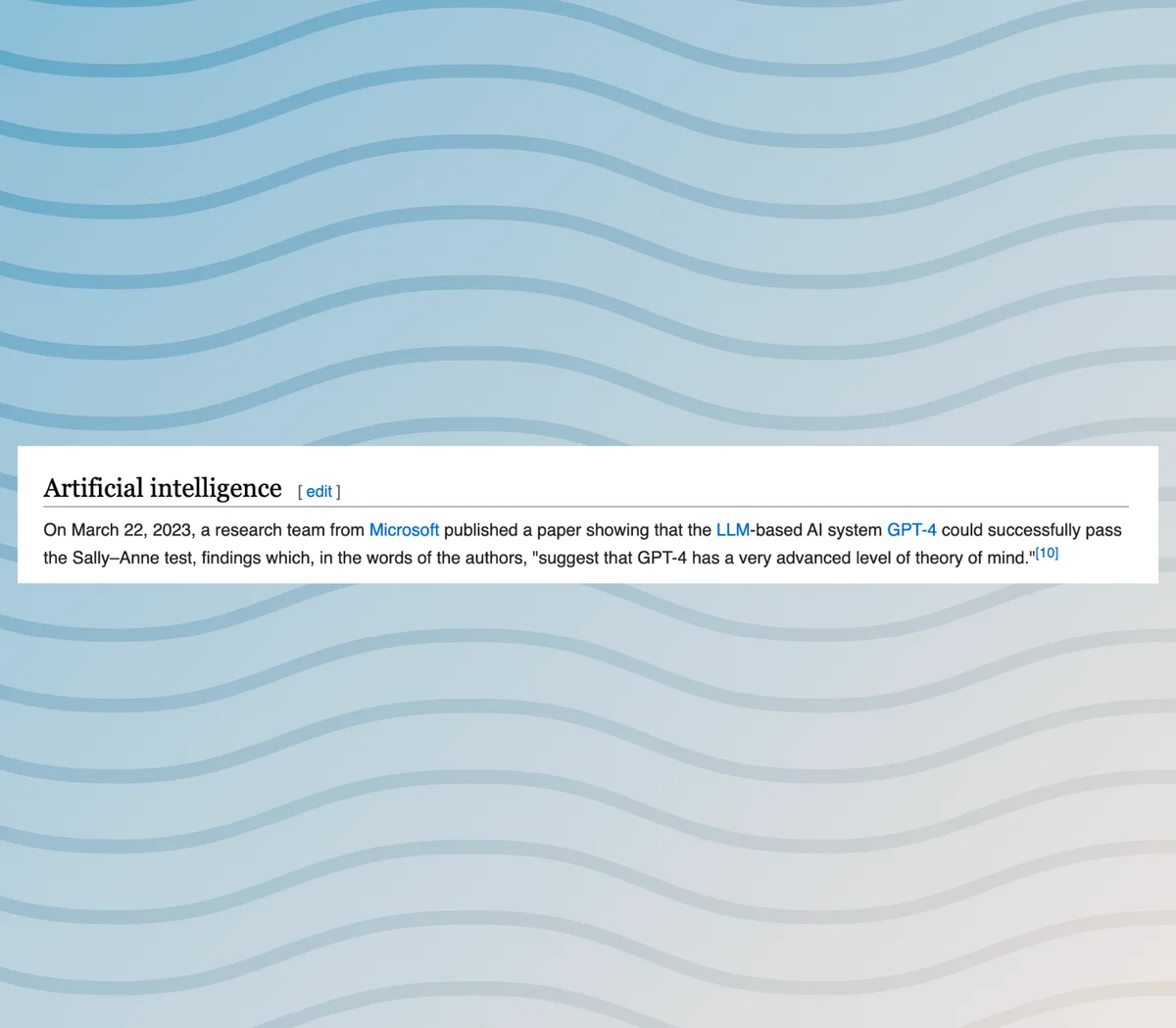
The Sally-Anne test, a well-known psychological evaluation, focuses specifically on the continuity of answers from one actor's perspective but not with their own. However, an intriguing observation arises in the context of GPT4. It appears that GPT4 encounters difficulties when the action required to answer a non-continuous scenario is not explicitly described as movement. This finding raises interesting questions about the limitations of GPT4's understanding of non-continuity in certain contexts.
In summary, through extensive testing, it has been observed that GPT4, and occasionally GPT3.5 as of 4 pm PT, demonstrate success in passing the Sally-Anne Test under specific conditions. Firstly, when the action involved is explicitly described as placement. Secondly, when the action is explicitly described as movement. Additionally, non-continuity in the scenarios can be attributed to either implicit or explicit reasons.
However, there are instances where these models fail to uphold their performance. These failures occur when the action is implicitly described as placement or movement. Moreover, they make a shared modality assumption regarding non-continuity, as evident in the example of a phone call.
These insights into the behavior of GPT4 and GPT3.5 in the Sally-Anne Test provide valuable information about the intricacies and limitations of language models' ability to understand and respond appropriately to scenarios involving false beliefs.
Maybe someone will fix the wikipedia page?
Credit: I have had the opportunity to work on evaluation framework design during my internships at @Meta and @allen_ai and owe a lot to my internship mentors for my thinking process here.
Cite This Page
@article{jaiswal2023nosallyannepass,
title = {No, GPT4 (RLHF’ed) Does Not Pass The Sally-Anne False Belief Test},
author = {Jaiswal, Mimansa},
journal = {mimansajaiswal.github.io},
year = {2023},
month = {Apr},
url = {https://mimansajaiswal.github.io/posts/no-sally-anne-pass-for-gpt4/}
}