
This post has two parts:
- Job Search Mechanics (including context, applying, and industry information), which you can read at
 LLM (ML) Job Interviews (Fall 2024) - Process, and,
LLM (ML) Job Interviews (Fall 2024) - Process, and, - Preparation Material and Overview of Questions, which you can continue reading below.
Last Updated: Feb 24, 2025
This is my personal process, which may work differently for others depending on their circumstances. I'm writing this in December 2024, based on my experience during Fall 2024. While the field of LLMs evolves rapidly and specific details may become outdated, the core principles should remain useful.
I want to be clear: this isn't a definitive guide or preparation manual, nor is it a guaranteed path to success. It's simply a record of what I did, without any claims about its effectiveness. If you find it helpful, wonderful—if not, I'd love to hear what worked for you instead. I'm sharing my experience, not prescribing a universal approach.
I typically avoid rewriting my personal posts using LLMs, but this content has been heavily edited, not generated (primarily using Notion AI, Claude 3.5 Sonnet and GPT-4o) to keep it concise and professional while maintaining my authentic voice—more or less.
Database View and Contributions
Some readers just want a simple list without the detailed explanations and context—and that's perfectly fine.
I've included two toggles below. The first shows these same resources in a Notion database view that you can freely explore—expand it, open it in a new page, or browse as needed.
The second toggle contains a contribution form for a separate database. I personally review all submissions to filter out spam, and I'll move valuable contributions to the main database. Contributing is entirely optional—while I don't expect anyone to do so, I welcome any worthwhile additions.
The collection currently lacks resources in certain areas, particularly multimodal and speech-based content. Though I can't write extensively about these topics myself, I'm happy to serve as a curator. If you have relevant resources to share, please use the form—I'll review submissions and incorporate valuable ones into the main database.
To view this content as a searchable database, expand this toggle. You can explore the embedded database by expanding it or opening it in a new page. (Last Updated: Feb 6, 2025)
To contribute to this collection, expand this toggle to find the submission form. I review all entries to filter out spam and add valuable contributions to the main database.
Content Storage
I use Notion pages for content storage. Though Capacities would have been ideal, its lack of a reliable output API meant I'd need to copy content into Notion anyway for this post. Additionally, Capacities doesn't support multi-user collaboration—a feature I occasionally need—and I prefer keeping my content in one place rather than scattered across multiple apps. I've ruled out Obsidian since I prefer rich-text block-based systems. Capacities does have one standout feature: the ability to mark individual blocks as database objects with properties while keeping the block content embedded in place. This feature is particularly valuable for learning, and I highly recommend it. This isn't meant to be a comprehensive overview of my content/knowledge management practices—just a brief explanation of my organizational preferences for interview preparation.
Classification
I maintained 7 major sections in my interview preparation page: Statistical Knowledge, ML Knowledge, ML Design, DSA Coding, ML Coding, Behavioral, and “I know of these papers”. Each section (other than the papers had a Question subpage with 4 categories: "Aced it," "Took time," "Didn't get it," and "Just saw it somewhere."
As mentioned in my ![]() LLM (ML) Job Interviews (Fall 2024) - Process post, I meticulously documented and categorized every interview question in the question bank, along with my performance evaluation. For those familiar with JEE preparation, this approach might sound familiar—it's my tried and tested method (though I failed at JEE), and it's the only system I know (fingers crossed for better results this time). Whenever questions repeated across interviews, I added comments in Notion noting their previous appearances and updated their categories based on my latest performance.
LLM (ML) Job Interviews (Fall 2024) - Process post, I meticulously documented and categorized every interview question in the question bank, along with my performance evaluation. For those familiar with JEE preparation, this approach might sound familiar—it's my tried and tested method (though I failed at JEE), and it's the only system I know (fingers crossed for better results this time). Whenever questions repeated across interviews, I added comments in Notion noting their previous appearances and updated their categories based on my latest performance.
Leetcode
Let me walk you through my LeetCode interview preparation approach. Companies consistently test candidates with LeetCode questions during interviews—yes, even startups. Here's the preparation strategy that worked for me.
Most companies don't allow code execution during interviews. While some Microsoft and Apple teams did permit running code (which was helpful), I learned to spot and prevent common mistakes without needing to test the code.
I tackled all questions from both recommended lists systematically. My first pass focused on finding solutions—whether brute force or optimized. After at least two days, I'd return to each question to implement an optimized solution. When successful, I'd move on. When stuck, I'd consult ChatGPT for the algorithm, implement it myself, and submit the solution. To maintain accurate progress tracking, I'd then intentionally submit an incorrect version to keep the question unmarked. After another two-day break following failed attempts, I'd try implementing the optimized version again.
I continued this process until I mastered all questions on the Grind 75 list, completed all easy and medium questions, and solved 50% of hard questions on the NeetCode 150 list.
ML/DL/LLM Coding
While these concepts can be coded given sufficient time and debugging capabilities, interview settings present unique challenges. You'll typically have just 25-35 minutes, need flawless execution, and must maintain precise matrix dimensions throughout. That's why practicing implementation is crucial, even if you're already comfortable with the concepts. To help you prepare, I've compiled repositories showcasing interview-style code examples, categorized into basic ML and LLMs. Following my Contextual interview, I expanded this collection by implementing various RAG/LLM inference papers—a category I found particularly engaging.
- For basic ML questions:
- One major omission in this resource is the implementation of basic neural networks using NumPy and PyTorch. To address this gap, I practiced coding feedforward neural networks (FNN), LSTMs, and RNNs from scratch using random values, then validated my implementations against online examples.
- For LLMs, I worked with the "Hands-on Large Language Models" repository. Rather than following the book directly, I turned the notebooks into fill-in-the-blank exercises and completed them systematically.
- Be prepared for questions about implementing different attention mechanisms — including cached, grouped query, multi-head, and single-head attention. You'll need to know how to code these using just NumPy and PyTorch. I recently found this post, which provides a thorough overview.
- Master implementing key components of the transformer architecture, including token embeddings, layer normalization, encoder layers, and techniques for integrating Mixture of Experts (MoE) into existing model architectures.
- I studied several codebases thoroughly, particularly the LLaMA model implementation and OLMo repository, to deepen my understanding of these concepts.
- Make sure to include dimensions in your variable names or comments. This helps with debugging, and interviewers frequently check dimensions to test your understanding—not just your ability to memorize. While I started by using comments, I later found Noam Shazeer's Shape Suffixes approach (
Shape Suffixes — Good Coding Style), which proved to be an excellent—perhaps even superior—method.
- For RAG/LLM inference papers, I practiced implementing core components: a basic embedding model with clustering capabilities, along with common decoding strategies like top-p, top-k, temperature control, and beam vs. greedy search. I also selected 10 papers from my favorite researchers and worked through their implementations independently. Since running the full models wasn't practical due to their size, I used LLM chatbots to validate my approaches, drawing on my ML expertise to critically evaluate their responses and identify potential issues.
- Finally, for additional practice, I worked through every question here using the same approach I used with LeetCode, though I rarely needed multiple attempts this time.

Statistics
I originally hadn't planned to include statistics in my preparation, but after being caught off guard by an unexpected Amazon interview loop early in my job search, I quickly realized I needed to. I then set out to find and practice statistics questions, using the resources listed below.
I'll be candid: there were many times when I struggled to remember concepts or needed to better understand the reasoning behind material I had simply memorized in college. I turned to ChatGPT and Claude to help clarify these topics. Though I always fact-checked their responses and ensured I had proper context, this approach actually improved my ability to explain concepts clearly and systematically (even if I still tended to ramble too much).
Some linear algebra concepts from here (I know it's not statistics, but it's still relevant)
For data science question preparation, I used this resource:
I found Chapter 5 of Chip Huyen's book particularly useful:
ML Knowledge
I organized the Machine Learning knowledge section into two parts: (a) ML fundamentals and (b) Large Language Models (LLMs) and Transformers. Looking back, I should have created three parts by making NLP fundamentals its own section. Depending on your specialization, this third section could instead cover Computer Vision with Vision Language Models, or other cutting-edge architectures.
ML Fundamentals
I began my preparation with this ML cheatsheet, which covers the fundamentals:
Next, I worked through chapters 7 and 8 of the ML interviews book:
I primarily used these two resources in my preparation. For each question I encountered, I documented it and explored potential follow-up questions. My study method was straightforward: I'd first attempt to answer the question independently. If successful, I'd use ChatGPT to generate follow-up questions and practice those too. When I couldn't answer a question, I'd start a fresh chat to research the topic, document my findings with notes and comments in Notion, and categorize it under the relevant toggle section.
Overall, you list should include:
- General breadth topics:
- Machine Learning Fundamentals: Supervised vs. unsupervised learning, logistic regression for classification, bag-of-words, bagging vs. boosting, decision trees/random forests, confusion matrix, regularization methods, clustering (k-means/k-medians), distance measures, convexity, loss functions.
- Statistics and Probability: Bias-variance tradeoff, imputation techniques, handling different dataset sizes, causal inference, statistical significance, regression analysis, Bayesian analysis, time series analysis, active learning, hypothesis testing, probability calculations.
- Models and Performance: Overfitting vs. underfitting, model performance monitoring, online/offline evaluation metrics.
- Dimensionality Reduction: Feature selection methods, matrix factorization, autoencoders, curse of dimensionality, PCA vs. t-SNE vs. MDS vs. autoencoders.
- Time Series Analysis: Stationary time series, frequency domain analysis, forecasting models.
- Neural Networks: Attention mechanisms, ReLU activation, deep neural networks (DNNs), recurrent neural networks (RNNs) including LSTMs, convolutional neural networks (CNNs), transformer models.
- Algorithms:
- Clustering: K-means, LDA, word2vec, hierarchical clustering, Mean-Shift, DBSCAN, expectation-maximization using GMM.
- Classification: Logistic regression, Naïve Bayes, k-nearest neighbors (KNN), decision trees, support vector machines (SVMs).
- Optimization: Unconstrained continuous optimization, gradient descent methods (batch vs. stochastic), maximizing continuous functions.
- Other Topics: Probability distributions and limit theorems, discriminative vs. generative models, methodology (online vs. offline learning, cross-validation), online experimentation (A/B testing), binary and multi-class classification, hyperparameters, feature engineering.
- Area-specific topics:
- Personalization/Recommendation Systems: Collaborative filtering, transformer architecture, active learning, self-attention, multiple attention heads, pooling methods, visualizing attention layers, ranking, multi-armed bandits (MABs), evaluation metrics, cold-start recommenders.
- Deep Learning: Transformers, dropout, normalization, maxout, softmax, word embeddings.
- Natural Language Processing: Latent Dirichlet Allocation (LDA), language modeling, handling sparse data, text normalization techniques, statistical language modeling, information retrieval, word2vec, CNNs, transformers.
- Computer Vision: Image and signal processing, linear algebra, image retrieval, CNNs, residual networks etc.
LLMs
I organized the material into 5 key sections:
- Architecture and Training: Covered transformer architecture fundamentals, pre-training versus fine-tuning approaches, training objectives (with emphasis on next-token prediction), tokenization methods, scaling laws, and parameter-efficient techniques like LoRA and Prefix Tuning.
- Generation Control: Explored methods for controlling model outputs through temperature and top-p sampling, effective prompt engineering, few-shot and in-context learning techniques, chain-of-thought prompting for complex reasoning, and strategies to minimize hallucinations.
- LLM Evaluation: Examined key metrics (including perplexity, ROUGE, and BLEU), standard benchmarks like MMLU and BigBench, approaches to human evaluation, and tools for bias detection and mitigation.
- Optimization and Deployment: Studied practical aspects like quantization, model distillation, inference optimization, prompt caching, load balancing, and cost-effective deployment strategies.
- Safety and Ethics: Focused on essential safeguards including content filtering, output sanitization, protection against jailbreaking attempts, and data privacy protocols for responsible LLM deployment.
One of the best analogies I learned came from Kevin Murphy's PML book, as quoted in Yuan's blog post ( Attention as Soft Dictionary Lookup).

While this architecture is widely known, I found it valuable as a framework for organizing my review of architecture-related papers and questions.
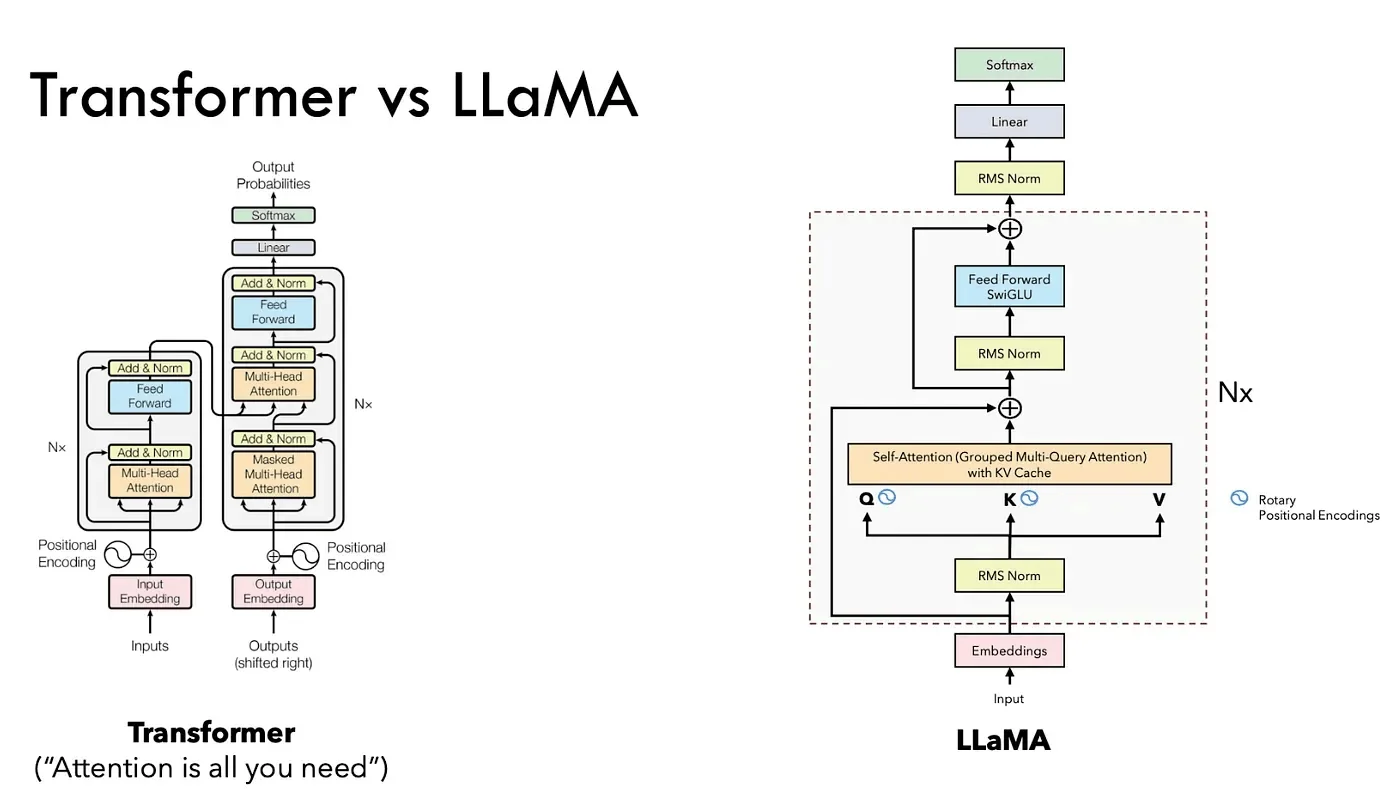
Here are the key resources and materials I studied:
- General content
- For LLM architecture, I focused on:
- Encoder vs decoder
- Training objectives As of Dec 30, 2024, MTP is an interesting mechanic to examine, and you should be prepared for questions about it. Deepseek-v3 has an implementation that you can reference.
- Self-attention (QKV sizes and weight matrices of QKV),
This video is great if you want to explain the intuition to someone else:
- Multi-head attention (concatenation of head outputs rather than averaging), grouped query attention, and other variants. Something to note: MLA became a popular mechanism while I was interviewing, so I learned about it during the process, aided by my "I know of these papers" section.
- Position-wise Feed-Forward Network (FFN size, ReLU activation, comparisons between ReLU, Swish, SiLU, and Swiglu variants),
- Positional embeddings (dimensions, sizing, learned embeddings, various embedding types, and Rotary Position Embeddings - RoPE),
- Layer normalization (underlying intuition and why LayerNorm parameters are separate from layer parameters),
- Cross-attention (comparing cross-attention with masked self-attention, understanding decoder-only architectures, and handling initial inputs in decoder-only models).
- For MoE, I started with this blogpost:
I then focused on Feed-Forward Networks (FFNs), studying their structure, placement, gating networks, routing mechanisms, load balancing, and training stability challenges. As of Dec 30, 2024, Deepseek's technical report offers valuable insights into practical MoE implementation.
- I focused on embeddings, studying token and position embeddings while building upon basic LLM embedding concepts. I specifically explored type/segment embeddings, directionality, and various tokenization approaches and methods.
- The key inference topics included:
- Attention mechanisms in training versus inference, including KV cache architecture and dimensionality
- Batch processing strategies and optimizations
- Decoding approaches, from simple greedy search to more sophisticated methods like beam search, along with sampling parameters (top-p, top-k, temperature) and their interplay
- Context window constraints and management
- Model quantization techniques
- Special tokens and their roles in chat-tuned models, plus early stopping criteria
- Long-range dependency handling through sparse attention mechanisms
And some reference material:
- The main fine-tuning topics included:
- Task-specific heads and adapter layers
- Parameter-efficient methods like LoRA (including mathematical foundations, comparisons between QLoRA and LoRA, and GaLore)
- Fine-tuning objectives and frameworks
- Hyperparameters and training approaches (supervised vs. unsupervised, instruction fine-tuning)
- Practical implementation steps (loading libraries, datasets, model configuration, tokenization, zero-shot inference, model evaluation)
- Direct Preference Optimization (DPO) in fine-tuning
I made sure to practice writing boilerplate code for the libraries section, which also ties into the LLM coding portion.
- Retrieval and RAG. Although Retrieval-Augmented Generation (RAG) could be viewed as its own topic, I've incorporated it as part of the broader LLM pipeline based on my hands-on experience and how it currently integrates with language models. Here are the resources I used:
The main RAG topics included:
- Knowledge base fundamentals (chunking, embeddings such as Word2Vec/Sentence-BERT/GPT models, contrastive loss, and vector storage)
- Query understanding
- Information retrieval components:
- Candidate generation (BM25, TF-IDF, Learning to Rank)
- Relevance scoring and dense retrieval
- Reranking and filtering
- Diversity sampling
- Context window selection
- Metadata extraction and result aggregation
- Context integration and response generation
- Evaluation metrics (NDCG, Mean Reciprocal Rank)
- RLHF (Reinforcement Learning from Human Feedback) is a topic I wish I had studied more thoroughly. Although I covered the basics—comparing PPO and DPO approaches and using ChatGPT to explore the subject through follow-up questions—I reached my knowledge limit fairly quickly. I still feel there's much more to learn. Here are some resources I used: Note that GRPO became a popular mechanism after my interviews, so I learned about it later, purely out of interest.
- Since I have extensive experience with synthetic data generation and evaluation, I kept my preparation for these topics minimal. Although I have access to various resources on synthetic data generation and evaluation (including one I created), I didn't need to review them in depth.
 I would appreciate suggestions for additional resources to include in this section.
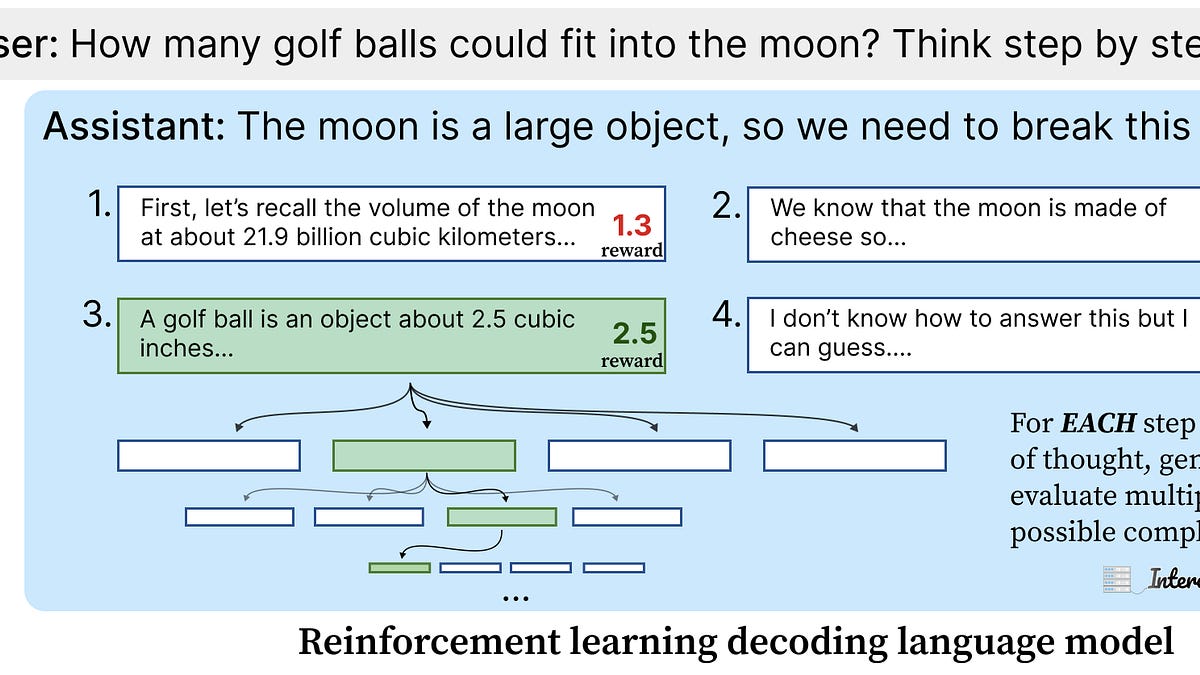
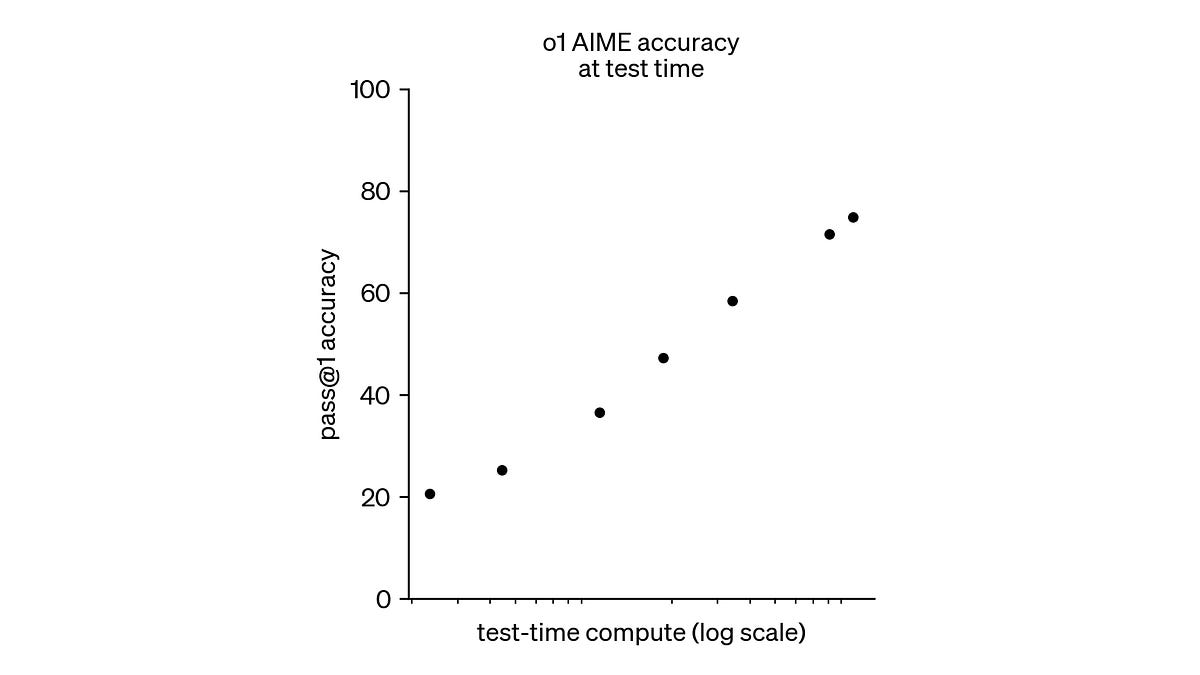
I would appreciate suggestions for additional resources to include in this section. - Since test-time computation was a relatively new concept and I already had limited knowledge of reinforcement learning techniques, I chose not to focus heavily on this area. I realized I would only be able to offer surface-level responses to related questions. Nevertheless, I did review these key resources:
- Since my knowledge of model optimization is limited, I welcome suggestions for additional reading material. Here are some resources that may be helpful:














ML (System) Design
While I didn't extensively prepare for these interviews, I was fortunate that the companies I targeted mainly focused on research experiment design rather than general system design questions. I encountered a few questions about recommendation systems and sentiment analysis design, which I handled as well as I could. Working with primarily research-based design questions was a relief.
When I first started interviewing, I made the mistake of hesitating to ask for clarification. After finding two helpful blog posts and a YouTube video about asking better questions, I created a ChatGPT prompt to practice. I would pose questions like "How would you set up a research question design for LLaMA Guard fine-tuning?" and use ChatGPT's suggested clarifying questions for practice. This helped me realize that it's completely fine to spend up to 10 minutes asking clarifying questions.
- Just the free section here:
- The tips here
- And these two youtube videos from Exponent
Another concern I had, which I've mentioned before, is that many people now default to using large language models for everything—even for tasks that simpler models like BERT could handle effectively, or when BM25 would work better than text embeddings with cosine similarity for information retrieval problems.
The key question is: When should we use these powerful generative models versus smaller discriminative models? After discussing this with my friends (Yash and June), they helped me craft the perfect response, which I've since memorized: "There are two ways I can approach this problem. One uses a discriminative method when optimization and latency are priorities, though it's more restrictive in its outputs. The other uses a generative method throughout, which may introduce latency but offers more flexibility. I can briefly discuss the pros and cons of both approaches, and then you can guide which path you'd prefer me to explore."
I really appreciate them suggesting this approach. I now consistently use this method when tackling any design questions.
Behavioral
You've probably heard of the STAR method by now. Stick to it—I did in my process too. I used natural transition phrases to avoid sounding rehearsed while keeping my responses structured. For example, I'd say "When this happened" or "For some context" as a personal reminder to describe the situation. Then I'd say "I had to do" to signal the task portion—these were cues for myself, not for the interviewer. I kept an eye on the clock to ensure I wasn't spending more than 30 seconds on any one part. Then I'd transition with phrases like "Here's what I did" or "I chose to do this," followed by "This was the result." I made sure the core response fit within two minutes. After that, I'd elaborate with additional details, often without prompting, but those first two minutes were always laser-focused.
I used this question bank set for behavioral questions and had stories for all of them.
Companies vary in their interview formats. While some may ask just a few behavioral questions per round, others—like Meta, with its extensive multi-round sessions containing up to 10 questions—can catch candidates unprepared.
When interviewing with multiple companies, you'll need distinct examples for each question within a single interview loop. Repeatedly telling the same stories during your job search can make your responses sound mechanical. Here's a useful tip from my advisor: take a sip of water after each paragraph to stay present and keep your responses natural.
This principle extends to your introduction. Using the same introduction repeatedly can make you appear stiff and disconnected. Though interviewers expect candidates to prepare their responses, a natural delivery creates better engagement with your interviewer.
I Know of These Papers
I deliberately chose the word "know" for an important reason—it captures multiple levels of familiarity: deeply reading papers, skimming them, finding them through social media, learning about them from others' presentations or discussions, and implementing them firsthand. This knowledge extends beyond academic papers to include Twitter threads, implementation guides, verified code examples, blog posts, and other sources. This broad scope is why I kept the heading intentionally general.
When interviewers ask open-ended questions, I make a point to cite my sources, saying things like "I learned this from a blog post" or "I've seen this discussed widely on Twitter." I maintain a broad collection of references and always stay transparent about my depth of understanding for each paper. As someone who's constantly online, I use Zotero and Raindrop to organize papers, related discussions, and emerging research. I skim every paper before adding it to my Zotero library, categorizing them by potential interview questions—which is exactly why I created this page.
I tracked open-ended questions in this section and researched relevant papers I may have overlooked, regularly expanding the list. I also maintained a collection of papers worth mentioning for specific topics, which proved invaluable. I'll share some resources to showcase recent papers that caught my attention. I should admit that my paper knowledge comes primarily from my somewhat excessive social media use rather than formal newsletters or collections. These resources might help you build your own reference library for handling open-ended questions.
Here are some resources I use to stay on top of the vast number of research papers in my field:
- People who share other people’s work and themselves work on topics that I am interested in
- People who share other people’s recent work (I prefer their curation)
I speed skim this list:
- People who summarize recent work or talk about ML fundamentals
- People whose work I follow



Finally
Interview experiences can vary greatly depending on the luck of the draw. A skilled interviewer makes the process flow naturally, and while strategically steering conversations toward your strengths is valuable, some interviewers may be less flexible in their approach. Since resource quality and relevance can differ widely, it's crucial to prioritize materials that directly support your specific career aspirations.
I'm eager to learn from others who have successfully juggled machine learning studies with their other life responsibilities. If you know of any useful interview preparation resources, please share them—I'll gladly add them here.
Good luck with your preparation!
Cite This Page
@article{jaiswal2024llmmljobintervi,
title = {LLM (ML) Job Interviews - Resources},
author = {Jaiswal, Mimansa},
journal = {mimansajaiswal.github.io},
year = {2024},
month = {Dec},
url = {https://mimansajaiswal.github.io/posts/llm-ml-job-interviews-resources/}
}